
今回ご紹介するPythonのプログラムは、Pythonで画像認識APIを利用して、インターネット上の画像データに適切な説明を自動でつけるプログラムです。
このプログラムを使うと、↓のようにAIが画像を認識して適切な説明をつけてくれます。
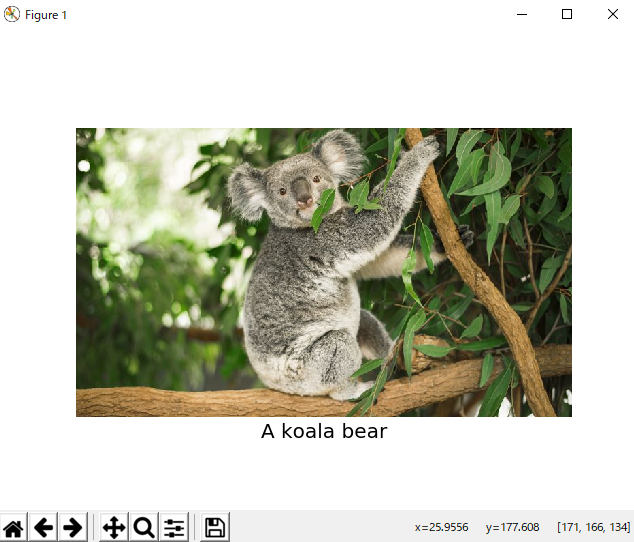
今回のプログラムではMicrosoftの「Computer Vision API」というものを利用します。
Computer Vision APIはAIが画像の認識、解析をしてくれるもので、アクセスすることによってその画像認識の技術を誰でも利用することができます。
 大体これぐらいの精度で画像を認識してくれます↑
大体これぐらいの精度で画像を認識してくれます↑
それでは早速、プログラムのソースコードを見ていきましょう。
プログラムのソースコード
ファイル名:script.py
import requests
# Jupyter notebookを使用している場合は、次の行のコメントアウトのための#を外してください。
# %matplotlib inline
import matplotlib.pyplot as plt
import json
from PIL import Image
from io import BytesIO
# 有効なサブスクリプションキーに置き換えて下さい。
subscription_key = "2d5b91ad2…(略)…b9f55c"
assert subscription_key
# REST API呼び出しでは、取得に使用したキーと同じリージョンから使用する必要があります。
# 取得したキー、たとえばwestusからサブスクリプションキーを取得した場合は、
# 以下のURLの"westcentralus"を"westus"に置き換えます。
# 無料トライアルサブスクリプションキーは"westcentralus"で生成されます。
# 無料のトライアルサブスクリプションキーを使用している場合は、変更する必要はありません。
vision_base_url = "https://westcentralus.api.cognitive.microsoft.com/vision/v2.0/"
analyze_url = vision_base_url + "analyze"
# 解析したい画像のURLを設定します
image_url = "https://www.worldatlas.com/r/w728-h425-c728x425/upload/55/37/ab/shutterstock-599462162.jpg"
headers = {'Ocp-Apim-Subscription-Key': subscription_key}
params = {'visualFeatures': 'Categories,Description,Color'}
data = {'url': image_url}
response = requests.post(analyze_url, headers=headers, params=params, json=data)
response.raise_for_status()
# 画像解析では画像を構成する様々な要素を得ることができ、
# 特に'description(=説明)'プロパティからその画像に最も関連性が高い要素を得られます
analysis = response.json()
print(json.dumps(analysis))
image_caption = analysis["description"]["captions"][0]["text"].capitalize()
# 画像をキャプションと共に描画する
image = Image.open(BytesIO(requests.get(image_url).content))
plt.imshow(image)
plt.axis("off")
_ = plt.title(image_caption, size="x-large", y=-0.1)
plt.show()
「#」で始まっている文はコメントアウトされます。
【プログラム実行前の準備】
Microsoft Computer VisionのAPIキーが必要となりますので、ない方は準備してください。
Pythonで画像認識するソースコードの詳細な解説
ではここからソースコードの詳細な解説に移りたいと思います。
プログラムで使うライブラリをimportする
1~7行目では、今回のプログラムに必要なライブラリをimportしています。
Pythonの【モジュール】の使い方。パッケージやライブラリとの違いも解説
requests
1行目のrequestsはPythonでhttp通信を行うためのライブラリです。
import requests
requestsについては、Pythonでスクレイピングしてタイトルと見出しを取得するプログラムの記事でも説明しましたので、詳しくはご覧ください。
requestsが起動(インストール)されていないと、http通信が出来ませんので、プログラム実行時にエラーになってしまいます。
※インストールがまだの方はコマンドプロンプトで
pip install requests
と入力してインストールして下さい。
Jupyter notebook
2~3行目に記載の Jupyter notebook とは、ノートブック形式で作成したプログラムを実行し、実行結果を記録しつつデータの分析作業も進めることができるツールです。
使用していない場合は特に気にする必要はありません。
# Jupyter notebookを使用している場合は、次の行のコメントを外してください。 # %matplotlib inline
matplotlib
import matplotlib.pyplot as plt
matplotlibは、計算結果をグラフなどで図表するためのライブラリです。
その中に含まれているpyplotモジュールとは、データのプロット(描画)を行うモジュールになります。
matplotlibをインストールすることで、Pythonの描画ライブラリで線・棒グラフや3Dグラフなどを描くのに役立ちます。
※インストールがまだの方はコマンドプロンプトで
pip install matplotlib
と入力してインストールして下さい。
またここでは、import文を使う際に「as」という文を付けています。
「as」を付けることでプログラム内でモジュール名を省略した名前で扱うことができます。
今回は「matplotlib.pyplot」をプログラム内では「
plt」という略称で使えるようにしています。
json
5行目ではjsonファイルを扱うため、まずjsonモジュールをimportします。
import json
jsonは、「JavaScript Object Notation」というデータフォーマットの略称になります。
jsonモジュールは、Pythonの標準モジュールなのでインストール不要です。
画像を処理するライブラリのPIL
6行目に記載のPILとは、「Python Image Library」の略で、画像処理するライブラリです。
from PIL import Image
(※インポート前にPILかPillowのインストール)
PILとPillowはどちらもPythonの画像処理ライブラリですが、PILは2011年を最後に開発が終了しました。
その後継としてPillowの開発が行われていますので、これからインストールする方にはPillowの方をおすすめします。
※インストールがまだの方はコマンドプロンプトで
pip install PIL
または
pip install Pillow
と入力してインストールして下さい。
BytesIO
7行目でのプログラムは、Pythonの標準ライブラリioから、BytesIOをimportします。
from io import BytesIO
BytesIOとは、メモリ上で画像や音声データを処理するための機能です。
ioモジュールは、Pythonの標準モジュールなのでインストール不要です。
Microsoft AzureのComputer Vision APIキーを設定
9~11行目では、プログラムの中で、AIを使った画像認識を利用できるようにするためにMicrosoft AzureのComputer Vision APIを設定しています。
# 有効なサブスクリプションキーに置き換えてください。 subscription_key = "2d5b91ad2…(略)…b9f55c" assert subscription_key
Microsoft Azureとは、Microsoftの提供しているクラウドサービスになります。
Computer Vision APIを使用するにはサブスクリプションキーの指定が必要です。
“2d5b91ad2…(略)…b9f55c”の部分は必ずご自身が取得したサブスクリプションキーの値に変更しておいてください。
その下のassert文でsubscription_keyに値がちゃんと設定されているかチェックしています。ちゃんと設定されていない場合は、エラーメッセージが出てプログラムが強制終了するようになっています。
REST APIのエンドポイント
13~20行目は、REST API呼び出しに使うURL(エンドポイント)についての記載です。
vision_base_url = "https://westcentralus.api.cognitive.microsoft.com/vision/v2.0/"
こちらは無料サブスクリプションプランの場合は特に変更する必要はありません。
参考:画像認識AIのMicrosoft Computer VisionのAPIキーを取得する方法
22行目は実際にAPIを呼び出すためのanalyze_urlを指定しています。
エンドポイントの後ろに付ける文字列は使いたいメソッドによって決まっています。
今回はComputer Vision APIの画像解析メソッドを使いたいので”analyze”という文字列を付加しています。
analyze_url = vision_base_url + "analyze"
解析したい画像のURLを設定
24~25行目
image_url = "https://www.worldatlas.com/r/w728-h425-c728x425/upload/55/37/ab/shutterstock-599462162.jpg"
のURLの部分は任意でご自身の解析したい画像のURLに差し替えてください。
なお画像によってはエラーとなる場合もありますので、その場合は別の画像URLを指定してください。
Computer Vision API呼び出し
headers
27行目に記載の headers にはAPI呼び出しに必要な情報が書かれています。
headers = {'Ocp-Apim-Subscription-Key': subscription_key}
Ocp-Apim-Subscription-KeyはMicrosoft Azureの特定のCognitiveサービスを利用する際にリクエストヘッダーに必ず記述しなければいけない要素です。
(参照:Azure Cognitive Services に対する要求の認証のページの「認証ヘッダー」のパートに詳しく書いてあります。)
ここにsubscription_key(APIキー)を指定することで、一人一人のAPIの認証を行うことが可能になります。
params
28行目に記載の params にはAPIに渡すパラメーターの値が書かれています。
params = {'visualFeatures': 'Categories,Description,Color'}
APIリクエストにおいて、パラメーターには一般的にこちらが欲しい条件を記述します。
指定できるパラメーターについてはComputer Vision APIのページの「Request parameters」の部分に書いてあります。
今回であれば、APIで画像認識したデータのうち、Categories(カテゴリー)、
Description(詳細な説明)、Color(色)を取得して下さいという条件を指定しています。
data
29行目に記載のdataには解析したい画像のURLが指定されています。
data = {'url': image_url}
APIにPOSTリクエスト
30~31行目は画像認識をするComputer Vision APIにPOSTリクエストを送っています。
response = requests.post(analyze_url, headers=headers, params=params, json=data) response.raise_for_status()
具体的には、requests.post でComputer Vision APIにリクエストを送信し、返ってきた解析結果を変数responseという変数に格納しています。
つまり、response変数には、APIリクエストを通して得られたレスポンスデータ(画像の詳細情報やステータスコード、jsonデータなど)が入っています。
次の行の raise_for_status()はresponseオブジェクトのステータスコードが200以外であればエラーを出してプログラムを止める関数です。
responseオブジェクト.raise_for_status()
一般的には上記のように記述します。もしresponseオブジェクトのステータスコードが404などの場合にはエラーを返してくれます。
つまり、APIから返ってきたレスポンスオブジェクトにエラーがないかチェックしています。
レスポンスオブジェクトからjsonデータの取得
37~38行目
response.json() でAPIから返ってきたレスポンスオブジェクトからJSONデータを取得して、analysisという変数に代入しています。
analysis = response.json() print(json.dumps(analysis))
json.dumps() 関数は()内のものをJSON形式へとデコード(変換)してくれる関数です。
json.dumps(analysis)によってanalysisをJSON形式へと変換した後にprintで出力しています。
JSONデータの要素の取り出し
39行目では、JSON形式に変換されたanalysisから具体的に要素を取り出してimage_captionという変数に代入しています。
image_caption = analysis["description"]["captions"][0]["text"].capitalize()
第1引数にキーの”description”第2引数にキーの”captions”第3引数にインデックスの0 第4引数にキーの”text”をそれぞれ指定して目的のテキストを抽出しています。
なおここでは’description’プロパティからテキストを取り出していますが
他にも’Categories’や’Color’プロパティも28行目でvisualFeaturesに指定して取得していますのでこれらから情報を取り出すことも可能です。
キーの部分を書き換えていろいろ試してみてください。
また、
文字列.capitalize()
で文字列の先頭の一文字を大文字、他の文字列を小文字に変換します。
抽出したテキストに capitalize() を使って先頭の1文字だけ大文字にして他は小文字に変換して整えます。
Image.openによる画像の表示
40~41行目
image = Image.open(BytesIO(requests.get(image_url).content))
画像を表示するためにまずは画像データのオープン処理を行います。
requests.get() でURL先のデータが取得できますが、今回は画像データ(=バイナリデータ)が対象ですので後ろに content を付けます。
その取得したバイナリデータをメモリに読み込むために BytesIO() を使います。
メモリに読み込まれた画像のバイナリデータを画像処理ライブラリのPIL(Pillow)に用意されているopenメソッドを使って開くことで画像のオープン処理は完了です。
オープンされた画像データを表示するためにはmatplotlib.pyplotモジュールに用意されている imshow() を使います。
plt.imshow(image)
座標軸の調整
画像を見やすくするために座標軸の調整を行います。
まずは座標軸を画像に重なって表示させたくないために非表示にします。
それにはmatplotlib.pyplotモジュールに用意されている axis() モジュールを使います。
引数に”off”を付けると座標軸を非表示にできます。
plt.axis("off")
次にComputer Vision APIで解析した結果のテキストをタイトルとして表示します。
それには title() を使います。
タイトル文字をデフォルトより大きくするためにキーワード引数の size に x-large を設定しています。
またタイトル位置をデフォルトの位置である上側の真ん中(x=0.5, y=1.0)から下側の真ん中に移動させるために引数の y を -0.1 に設定しています。
なおここでは
変数 = plt.title(image_caption, size=”x-large”, y=-0.1)
と記載しておりますが、この場合変数には「matplotlib.text.Textクラスのインスタンス」が代入されます。
ただしこのプログラム内でのtitle()メソッドはプロットにタイトルを表示させるためだけに使われており、title()メソッドの返すインスタンスは使用しておりません。
なのでここでは「使用されない変数」という意味の「_(アンダーバー)」が変数名として使われています。
またはアンダーバー変数を省略して
plt.title(image_caption, size=”x-large”, y=-0.1)
と記述してもOKです。
_ = plt.title(image_caption, size="x-large", y=-0.1)
実際に画像を表示する
以上で座標軸の設定が終わりましたので、plt.show() で画像を表示してみましょう。
plt.show()
以上の方法で、画像解析を用いて自動的に適切な説明をつけて画像を表示させることが出来ます。
すぐに使いたい方向けのマニュアル
1.パソコンにPythonをインストールしていない方は、まずインストールしましょう。
こちらのページを参考にして下さい。
2.マイドキュメントなどに適当な名前のフォルダを作り、その中に新規テキストファイル(.txt)を作成、プログラムのソースコードを張り付けて、拡張子を.txtから.pyに変換してscript.pyという名前で保存します。
こちら↓を参考にしながらMicrosoft AzureのComputer VisionのAPIキーを取得しましょう。
画像認識AIのMicrosoft Computer VisionのAPIキーを取得する方法
そして、script.pyを開き、コードの11行目の
subscription_key = "2d5b91ad2…(略)…b9f55c"
の2d5b91ad2…(略)…b9f55cの部分を自分のAPIキーと置き換えて下さい。
また、コードの23行目の
image_url = "https://www.worldatlas.com/r/w728-h425-c728x425/upload/55/37/ab/shutterstock-599462162.jpg"
上記のimage_urlの部分ですが、
“https://www.worldatlas.com/r/w728-h425-c728x425/upload/55/37/ab/shutterstock-599462162.jpg”のところに自分の解析したい画像のURLを入れて下さい。
ここまでできたら上書き保存します。
3.Windowsならコマンドプロンプト、Macならターミナルを開きファイルを置いてあるパス(URL)へ移動します。
移動の方法はコマンドプロンプトでもターミナルでも
cd ファイルが置いてあるパス
のコマンドで移動できます。
4.コマンドプロンプト、またはターミナルで
カレントディレクトリにいることを確認して
pip install requests
pip install matplotlib
pip install Pillow
のコマンドをそれぞれ記入してEnterを押します。
これでプログラムに必要なライブラリである、requestsとmatplotlibとPillowをインストールできます。
最後に
Python script.py
と入力してEnterを押します。
これで画像とともに説明が表示されたら終了です。
エラー報告はコメント欄にお願いいたします。


コメント