
みなさん仕事や勉強で、何かについてのデータを集めて記録する作業をした経験はありませんか。
少し前まで自分もWebサイトと睨めっこしながら、データを探してはコピーペーストを繰り返していました。
しかしPythonを使えば、Webサイトへのアクセスもexcelファイルの操作も自動化できます。
手作業で行っていたら数時間かかるようなデータ収集も一瞬で終わらせることが可能です。
今回は株価のデータをスクレイピングして、Excelファイルに保存するプログラムです。
プログラムを実行すると、株価データをまとめたExcelファイルが数秒で作成されます。
.jpg)
プログラムのソースコード
#ライブラリをインポートfrom bs4 import BeautifulSoup
import requests
import openpyxl
#調べたいデータを指定
code = 調べたい銘柄コード
year = 調べたいデータの年号
#URLを取得
url = "https://kabuoji3.com/stock/"+str(code)+"/"+str(year)+"/"
headers = {"User-Agent": "自分のユーザーエージェントを記入"}
soup = BeautifulSoup(requests.get(url, headers = headers).content,'html.parser')
title = soup.select_one("span.jp").text
#Excelファイルを作成
wb = openpyxl.Workbook()
ws = wb.active
ws.title = str(title)
ws['A1'].value = '日付'
ws['B1'].value = '始値'
ws['C1'].value = '高値'
ws['D1'].value = '安値'
ws['E1'].value = '終値'
ws['F1'].value = '出来高'
ws['G1'].value = '終値調整'
#株価を取り出す
all_tr = soup.find_all('tr')
for i in range(1,len(all_tr)):
tr = all_tr[i].find_all('td') #リスト型
for n,td in enumerate(tr, 1)):
new_cell = ws.cell(row=(i+1), column=n)
new_cell.value = td.text
#ワークブックをExcelファイルとして保存
wb.save(str(title)+'.xlsx')
禁止されているサイトはスクレイピングしない
サイトによってはWebブラウザ以外からのアクセスや、スクレイピングを許可していない場合があります。
たとえば株価を調べるにしても、Yahoo!ファイナンスではスクレイピングは禁止されています。
ですので、スクレイピングを禁止していないサイトから行いましょう。
今回はスクレイピングを許可している株式投資メモさんのデータをお借りします。(現在アクセスすると403エラーが出るようになっています。)
robots.txtでスクレイピングOKかチェック
WebページがスクレイピングOKか確認するには、robots.txtをチェックします。
robots.txtとは、ページのコンテンツをスクレイピングされないようにするファイルです。
robots.txtの内容がAllowの場合、スクレイピングが許可されています。
robots.txtの内容がDisallowの場合、ツールなどを使ったアクセスを禁止しています。
株式投資メモさんのrobots.txtにアクセスして確認したところ、Allowと書かれていたのでOKです。
プログラム実行前に必要な準備
PythonでWebページをスクレイピング・Excelファイルを操作するには、外部ライブラリのインストールが必要です。
pip install bs4
pip install requests
pip install openpyxl
↑の3つを実行して、プログラムを実行する前にインストールしておきます。
調べたい株の銘柄を記入
7〜8行目:
code = 調べたい銘柄コード
year = 調べたい年号
プログラムのソースコードに、調べたいデータの銘柄・年号を記述しておきます。
変数codeには、チェックしたい株式の銘柄コードを記入します。変数yearには、チェックしたい期間の年号を記入します。
今回は例として、バンダイナムコホールディングスさんの株価を調べてみようと思います。
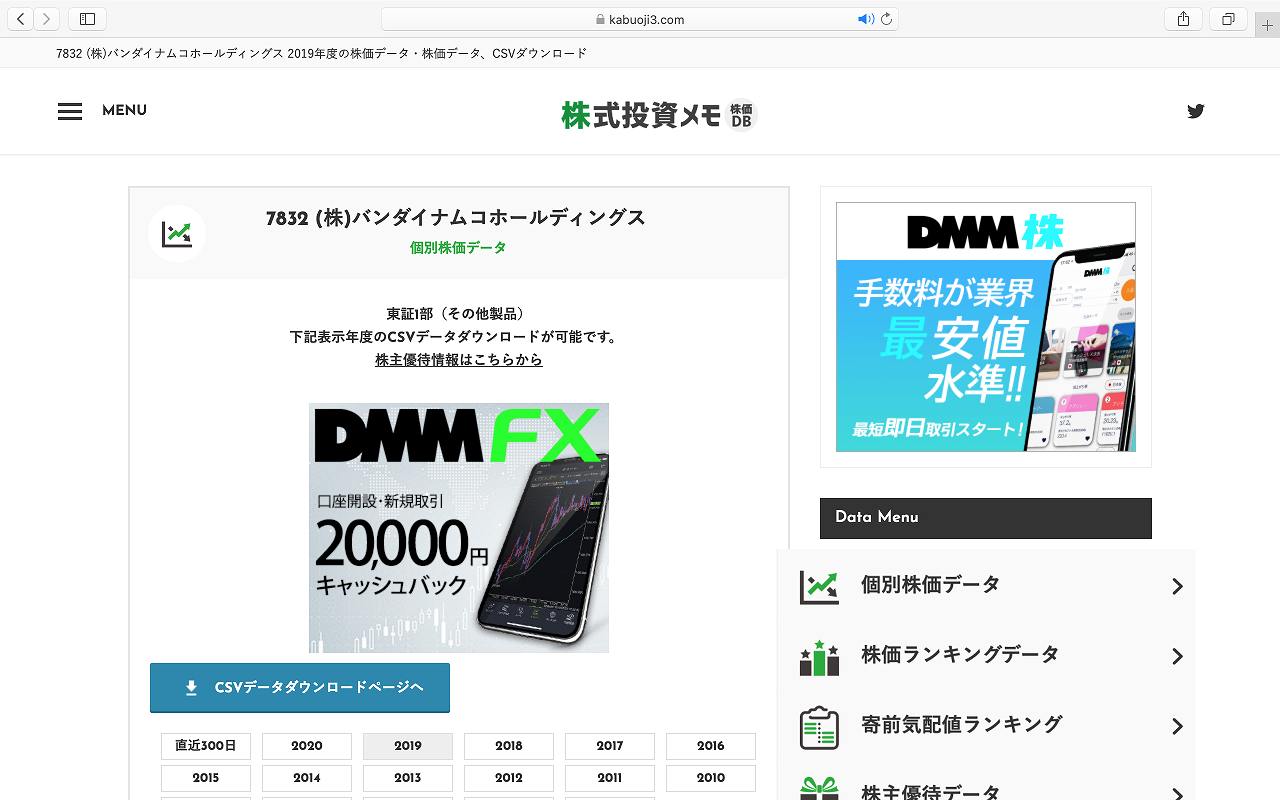
(例)バンダイナムコホールディングス(銘柄コード7832)の2019年のデータを調べたい場合
code = 7832
year = 2019
変数codeと変数yearはそれぞれ、銘柄コードの7832と調べたい年の2019を記入します。
ユーザーエージェントを記載
Pythonプログラムを使ってスクレイピングを行うと、
403 Forbidden:You don’t have permission to access on this server
というエラーが表示されてしまうことがあります。
簡単にいうと、「アクセスしたページは存在しますがあなたには見せません」という意味のエラーです。
このエラーの原因は、ヘッダーにユーザーエージェントを記載せずにリクエストすることにあります。
- ヘッダーとは、ページにアクセスする際にやり取りする注意書きのようなデータ
- ユーザーエージェントは、どのようなプログラムや環境でアクセスしているかという情報
ですので、こちらが何者であるかユーザーエージェントで自己紹介をする必要があります。
ユーザーエージェントの確認方法
エラーを回避するために、以下の処理でユーザーエージェントを指定してください。
-
- 「確認くん」にアクセス
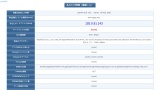
-
- ソースコードにコピーペースト
ページ内の「現在のブラウザ」という部分がユーザーエージェントの情報になります。
プログラムのコードのheaders部分に、以下の例のように情報をコピーペーストします。
11行目:
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1 Safari/605.1.15 "}
プログラムについての解説
ここからはプログラムのソースコードについて1行ずつみていきます。
1〜3行目:
from bs4 import BeautifulSoup
import requests
import openpyxl
今回のプログラムで使うライブラリをインポートします。
調べたい銘柄コード・年号を指定
6〜7行目
code = 調べたい銘柄コード
year = 調べたい年号
プログラム実行前に記入した銘柄コードと年号が2つの変数にセットされます。
変数code=チェックしたい株式の銘柄コード
変数year=チェックしたい期間の年号
(例)バンダイナムコホールディングス(銘柄コード7832)の2019年のデータを調べたい場合
変数codeは7832、変数yearは2019となります。
調べたい株価データのURLを取得
今回のページ株式投資メモさんでは株価データを、
https://kabuoji3.com/stock/銘柄コード/年
というパターンのURLで公開しています。
10行目:
url = "https://kabuoji3.com/stock/"+str(code)+"/"+str(year)+"/"
銘柄(変数code)と年(変数year)を代入することで、スクレイピングしたい株価のURLが完成します。
こうして完成した、今回調べたい株価データのURLを変数urlとします。
(例)バンダイナムコホールディングス(銘柄コード7832)の2019年のデータを調べたい場合
https://kabuoji3.com/stock/7832/2019
というURLが作成されます。
Beautifulsoupオブジェクトを取得
12行目:
soup = BeautifulSoup(requests.get(url, headers = headers).content)
まずrequests.get()で、指定した銘柄コードの株価のページにアクセスします。
変数urlでアクセスするURLを指定、変数headerでユーザーエージェントを送信しています。
そして返り値のResponseオブジェクトから、content属性でバイナリデータを取り出します。
そのバイナリデータをBeautifulSoup()でパースして、BeautifulSoupオブジェクトを作成します。
これでWebページをhtml要素ごとに分けて、解析しやすいように整理できました。
株価を調べたい会社の名前を取得
さっそくBeatufulSoupオブジェクトから欲しい情報だけを取り出してみます。
まずはページのhtml要素を使って絞り込んで、調べたい会社の名前を取得します。
13行目:
title = soup.select_one("span.jp").text
soup.select_one()で、BeatufulSoupオブジェクトから指定した要素だけを取り出します。
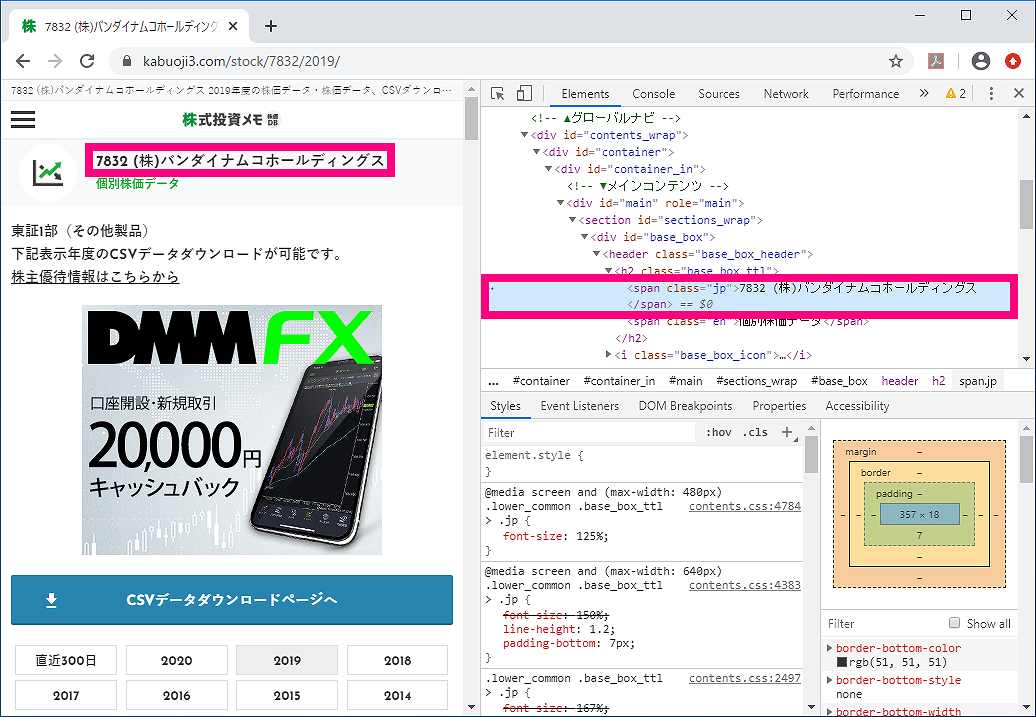
デベロッパーツールでhtml構造を確認してみると、画像のように
<span class=”jp”>
という要素に会社名があるようです。
そこで今回は(“span.jp”)と指定して、会社名のspanクラスだけを取り出しています。
spanクラスを取得したら、text属性で文字列を取り出して、会社名を変数titleとします。
(例)バンダイナムコホールディングス(銘柄コード7832)の2019年のデータを調べたい場合
変数titleは「7832 (株)バンダイナムコホールディングス」という文字列になります。
データを記入するワークシートを作成
取り出した株価のデータを記入するため、先にワークブックを準備しておきます。
16行目:
wb = openpyxl.Workbook()
Workbook()で、空のワークブックを新規作成して、変数wbとします。
17行目:
ws = wb.active
wb.activeで、ワークブック内のアクティブなワークシートを選択して、変数wsとします。
18行目:
ws.title = str(title)
ws.titleで、ワークシートの名前を変更します。
先ほど取得した会社名(変数title)がワークシートの名前になります。
19〜25行目:
ws['A1'].value = '日付' ws['B1'].value = '始値' ws['C1'].value = '高値' ws['D1'].value = '安値' ws['E1'].value = '終値' ws['F1'].value = '出来高' ws['G1'].value = '終値調整'
ワークシートの1番上の行(A1〜G1)に見出しの値を記入します。
ws[‘セル番号’].value()で、それぞれ指定したセルに値を入力します。
(例)バンダイナムコホールディングス(銘柄コード7832)の2019年のデータを調べたい場合
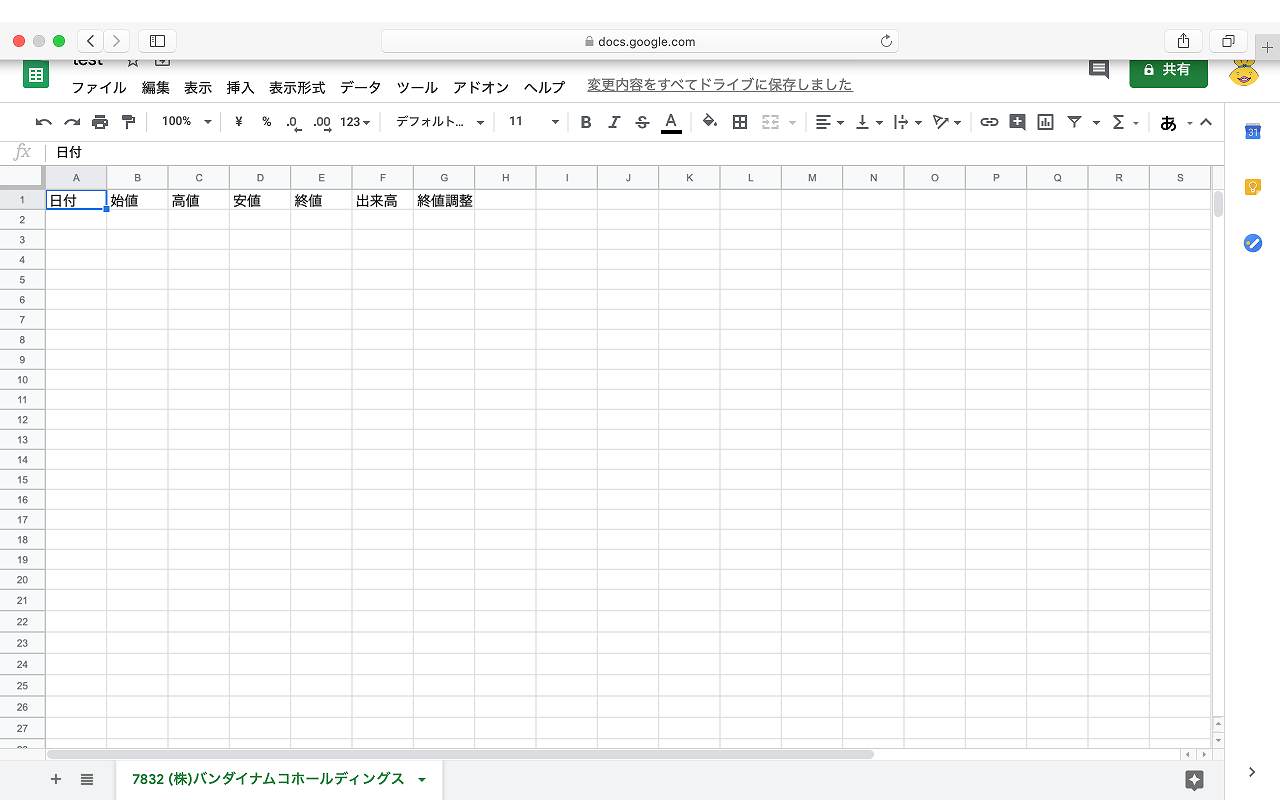
画像のように、「7832 (株)バンダイナムコホールディングス」というワークシートが作成されます。
ページから株価を取り出す
さっきと同じようにBeatufulSoupオブジェクトから欲しいデータだけを取り出します。
今度は株価のデータを取り出したいので、株価がhtml内でどの要素にあるかを調べます。
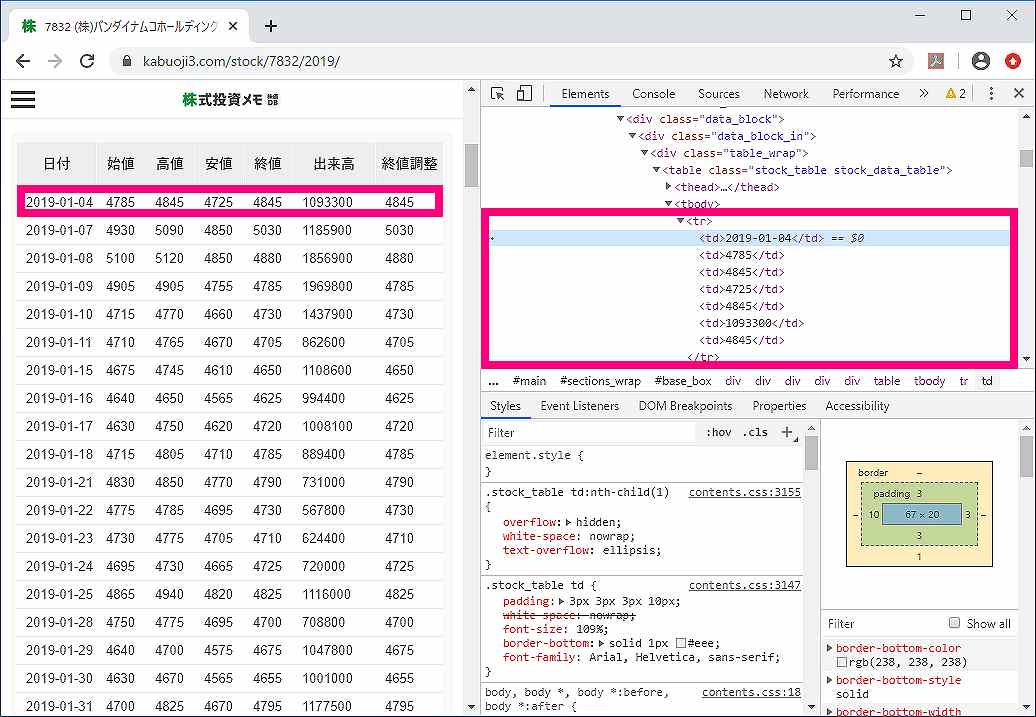
デベロッパーツールでhtml構造を確認してみると、
<tr>タグ
の要素に、日付〜終値調整までその日の株価についての全データがあることがわかります。
指定した年の全データを取り出す
28行目:
all_tr = soup.find_all('tr')
まずはsoup.find_all()で、ページにあるtrタグを全て取り出します。
すると、ページにある1年分全ての株価データが取得できます。
そして取り出したtrタグの一覧リストを、変数tag_trとします。
1日ごとの株価データを1つずつ取り出す
29行目:
for i in range(1,len(all_tr)):
for文で、ページにあるtrタグの個数を1つずつ取り出してループ処理します。
len(all_tr)は、リスト型(変数all_tr)の要素数なので、ページにあるtrタグの個数。
range(1,len(all_tr))は、「1からtrタグの個数までの数値」を集めたリストになります。
30行目:
tr = all_tr[i].find_all('td')
tag_tr[i]で、ページ内のtrタグの一覧リスト(変数all_tr)からi番目のtrタグを1つ取り出します。
つづいてfing_all()で、取り出したtrタグにあるtdタグを全て抽出します。
こうして取得した、1つのtrタグ内にあるtdタグを全て集めたリストを変数trとします。
これで変数trに指定した1日分の株価データを取り出すことができました。
1日の全データから各データを取り出す
変数trはある1日の日付〜終値調整のデータを全てまとめたリストです。
ですので、リストにある1日分の株価データをそれぞれの項目ごとに取り出して処理します。
31行目:
for n,word in enumerate(tr, 1):
enumerate()を使ったfor文で、リストからインデックス番号とデータの値を1セットずつ取り出します。
デフォルトだと最初のインデックス番号は0ですが、引数の(tr, 1)で1から数えるようにしました。
- 変数n=リスト内でのインデックス番号(※1から数え始める)
- 変数td=リストから取り出したデータの数値(tdタグ)
デベロッパーツールでわかるように、trタグとtdタグは下のような関係になっています。
<tr> <td>日付</td> <td>始値</td> <td>高値</td> <td>安値</td> <td>終値</td> <td>出来高</td> <td>終値調整</td> </tr>
たとえば変数n=1の場合、1番目のtdタグである日付の数値が変数tdに取り出されます。
データを記入するセルを指定
32行目:
new_cell = ws.cell(row=(i+1), column=n)
ws.cell()で、ワークシート上にあるセルを1つ指定して、変数new_cellとします。
データを記入するセルは、以下のようにして行・列で指定しています。
-
row = i+1
ワークシートにあるデータを記入したいセルの行を決めます。
1行目は見出しがあるので、2行目以降に記入するため、i+1とします。
-
column = n
ワークシートにあるデータを記入したいセルの列を決めます。
変数nと同じ数、n列目のセルが指定されます。
セルに株価を記入する
33行目:
new_cell.value = td.text
new_cell.valueで、指定したセル(変数new_cell)に取り出したデータの数値(変数td)を記入します。
(i番目のtrタグにあるn番目のtdタグ)のデータが、(n列・i+1行)のセルに記入されます。
その後、全てのデータ(変数all_trにある全てのtdタグ)を記入するまで同じ処理を繰り返します。
全てのデータを記入したら、最後にExcelファイルとして保存します。
Excelファイルに保存して完成
36行目:
wb.save(str(title)+'.xlsx')
wb.saveで、ワークブックをExcelファイルとして保存します。
引数の変数titleは会社名を表すので、「会社名.xlsx」というファイル名で保存されます。
プログラムを実行すると、株価データをまとめたExcelファイルが作成されます。
プログラムの解説はここまでになります。

コメント