
以前にMicrosoft Computer VisionAPIで画像解析する記事を書いたのですが、今回はその続きで解析した画像の説明を使ってファイル名を自動でリネームするというプログラムです。
これがあれば複数枚の画像に一気に適切な名前をAIを利用して自動でつけることが可能になります↓
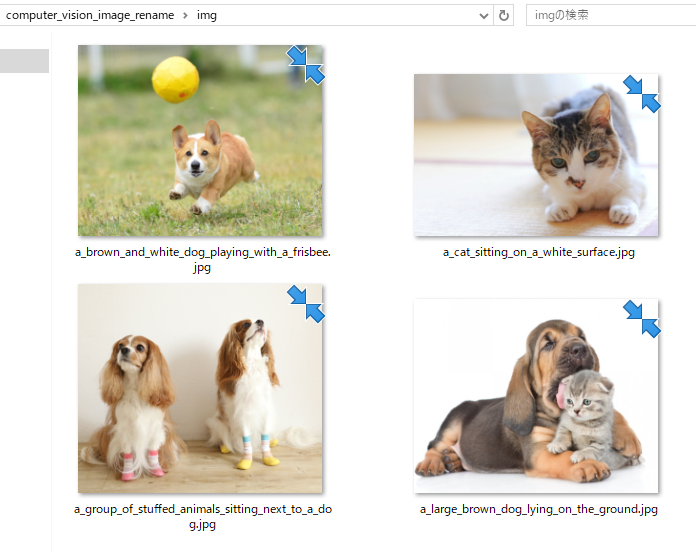
ですので、自分でリネームする手間を省けます。
まずは完成したプログラムのソースコードを貼っておきます。
プログラムのソースコード
ファイル名:cv_demo.py
# copyright symfony@lancers
# API reference :
# https://westus.dev.cognitive.microsoft.com/docs/services/5adf991815e1060e6355ad44/operations/56f91f2e778daf14a499e1fa
# 参考 : https://ledge.ai/microsoft-computer-vision-api/
# 機能概要 : img フォルダ中の画像をAI解析し、ファイルのリネームを行います。
# 使い方 : python3 cv_demo.py
# 注意 : サブスクリプションキーは変更してください
import requests
import glob
import os
import time
subscription_key = "aaa"
assert subscription_key
vision_base_url = "https://westcentralus.api.cognitive.microsoft.com/vision/v2.0/"
analyze_url = vision_base_url + "analyze"
# ファイル名を変更
def file_rename(list_1, list_2):
for i in range(len(list_1)):
os.rename(list_1[i], './img/' + list_2[i] + '.jpg')
def ms_computer_vision_api(filepath):
headers = {'Ocp-Apim-Subscription-Key': subscription_key,'Content-Type': 'application/octet-stream'}
params = {'visualFeatures': 'Categories,Description,Color'}
img = open(filepath, 'rb')
img_byte = img.read()
response = requests.post(analyze_url, data=img_byte, headers=headers, params=params)
response.raise_for_status()
return response.json()
if __name__ == "__main__":
# 画像ファイルを配列に格納
image_file = glob.glob('./img/*')
vision_file_name = []
start = time.time()
# Computer Vision APIにリクエストして結果を取得
for i in range(len(image_file)):
json_data = ms_computer_vision_api(image_file[i])
# 生成された文章を取得
file_name = json_data['description']['captions'][0]['text']
vision_file_name.append(file_name)
# 文章の空白をファイル名用にアンダーバーに修正
for i in range(len(vision_file_name)):
vision_file_name[i] = vision_file_name[i].replace(' ', '_')
file_rename(image_file,vision_file_name)
# 経過時間を出力
# print("elapsed_time:{0}".format(time.time() - start) + "[sec]")
【プログラム実行前の準備】
画像の解析には、Microsoftの画像解析AIを用いて行います。
今回はMicrosoft AzureのComputer Vision APIというサービスで画像を解析します。
Computer Vision APIは画像の分類や説明を行うことができたり、手書き文字を認識することもできます。
Computer Vision APIキーの取得
Computer Vision APIを使用するには事前にMicrosoft Azureのアカウントを開設してComputer VisionのAPIキーを事前に取得する必要があります。
画像認識AIのMicrosoft computer visionのAPIキーを取得する方法
を参考に準備しておいてください。
ソースコードの書き換え
このプログラムでは、ソースコードにサブスクリプションキーを書き加える必要があります。
cv_demo.pyをメモ帳などで開き、ソースコードの12行目を書き換えましょう。
subscription_key = "aaa"
この”aaa”の部分を、ご自身のサブスクリプションキーに書き換えて、同じ名前で上書き保存してください。
imgフォルダに解析したいJPEG画像を入れておく
今回のプログラムでは、imgという名前のフォルダにあるJPEG画像ファイルがリネームされます。
ですので、imgという名前のフォルダを予めcv_demo.pyと同じ場所に作成して、解析したい画像ファイルを入れておく必要があります。
APIの制限により1度に処理できる画像の枚数は16枚までなので、フォルダ内の画像ファイルは16枚以内に抑えておきましょう。
requestsライブラリのインストール
今回のプログラムでは、requestsという外部ライブラリが必要です。
インストールがまだの方はプログラム実行前に
Macの場合はターミナル、Windowsの場合はコマンドプロンプトから、
pip install requests
を実行してインストールを済ませておいてください。
ソースコードの詳細な解説
ではここからソースコードの詳細な解説に移りたいと思います。
cv_demo.pyで使うライブラリをimport
8~11行目:
import requests import glob import os import time
cv_demo.pyを動かすために必要となる、4つのライブラリをimportします。
requestsモジュール
8行目:
import requests
requestsはHTTP通信を通してWebページの情報を取得するための外部ライブラリです。
以前に書いたPythonでスクレイピングした時の解説も参考にしてください。
globモジュール
9行目:
import glob
globはフォルダ内のファイルパス名を取得するための標準ライブラリです。
globモジュールについては以前に書いたこちらの解説を読むと理解できると思います。
osモジュール
10行目:
import os
osはファイルやパスの名前を操作するためのモジュールです。
以前の解説も参考になります。
timeモジュール
11行目:
import time
timeは時間に関する情報を扱うための標準ライブラリです。
具体的には、現在時刻の表示や経過時間を測定したり、2つの時間の時間差を算出したりできます。
画像の解析を行うサーバーにアクセス
Computer Vision APIで画像を解析するには、サーバーにアクセスする必要があります。
サーバーにアクセスするために必要なサーバーのURLとサブスクリプションキーを指定します。
サブスクリプションキーを設定
12行目:
subscription_key = "aaa"
Computer Vision APIを使用するのに必要なサブスクリプションキーを指定しています。
今回は例として、サブスクリプションキーを”aaa”としています。
aaaの部分は必ずご自身が取得したサブスクリプションキーの値に変更しておいてください。
サブスクリプションキーの取得がまだの方は
画像認識AIのMicrosoft computer visionのAPIキーを取得する方法
を参考に取得してから、ソースコードのサブスクリプションキーの値を変更してください。
サブスクリプションキーのチェック
13行目:
assert subscription_key
subscription_keyに正しいAPIキーがちゃんと設定されているかチェックしています。
もし間違ったサブスクリプションキーを入れてしまったら、エラーメッセージが出るようになっています。
Computer Vision APIのURLを設定
14~15行目:
vision_base_url = "https://westcentralus.api.cognitive.microsoft.com/vision/v2.0/" analyze_url = vision_base_url + "analyze"
アクセスしたいAPIの住所であるURLを設定しています。
このURLの事を「エンドポイント」と呼びます。
このエンドポイントは
のままにしておいて下さい。
ファイル名をリネームする関数を定義
16~19行目:
# ファイル名を変更
def file_rename(list_1, list_2):
for i in range(len(list_1)):
os.rename(list_1[i], './img/' + list_2[i] + '.jpg')
この部分はdef文によって、file_renameという関数を定義しています。
具体的にはlist_1とlist_2という2つのリストを引数として、list_1の要素全てのファイル名を
の形にリネームしています。
細かく解説していきます。
18行目:
for i in range(len(list_1)):
range()の要素を1つずつ i に代入して、for 文に続く処理を行っていきます。
ここは繰り返し処理になります。
len(list_1)で、list_1に入っているオブジェクトの要素数を取得します。
len()は、文字列の文字数やリストの要素数を取得できる関数です。
range(len(list_1))で、0から「len(list_1)-1」までの値が格納されたリストを作成します。
range()は、0から「()の数値 – 1」までの値が格納されたリストを作成する関数です。
例えば、list_1の要素数が5つだった場合は
len(list_1) = 5
となるので、rangeのリストは 0から5-1の要素となり、
となります。
19行目:
os.rename(list_1[i], './img/' + list_2[i] + '.jpg')
の形で引数1のファイル名を、引数2のファイル名に変更します。
つまり上記の例ですと、list_1[i] というファイル名が ./img/’ + list_2[i] + ‘.jpg
に変更されています。
ここまでの処理が、file_renameという関数名で扱われます。
Computer Vision APIを使って画像ファイルを解析する関数を定義
20~28行目:
# 画像ファイルを解析
def ms_computer_vision_api(filepath):
headers = {'Ocp-Apim-Subscription-Key': subscription_key, 'Content-Type': 'application/octet-stream'}
params = {'visualFeatures': 'Description'}
img = open(filepath, 'rb')
img_byte = img.read()
response = requests.post(analyze_url, data=img_byte, headers=headers, params=params)
response.raise_for_status()
return response.json()
def文によって、ms_computer_vision_apiという関数を定義します。
filepathにある画像ファイルをComputer Vision APIで解析して、解析結果のデータを受け取る関数です。
22行目:
headers = {'Ocp-Apim-Subscription-Key': subscription_key, 'Content-Type': 'application/octet-stream'}
Computer Vision API呼び出しに必要なリクエストヘッダーを準備します。
'Ocp-Apim-Subscription-Key'では、サブスクリプションキーを指定します。
'Content-Type'には、「メディアタイプが不特定形式」という意味の
'application/octet-stream'というMIMEタイプが指定されています。
MIMEタイプが何か分からない方は下記の説明が分かりやすく解説してあります。
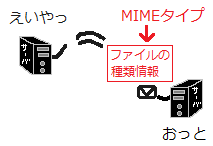
「このファイルは、こんな種類のファイルですよ」な情報がMIMEタイプです。
ホームページを表示するとき、ホームページのファイルが置いてあるコンピュータ(Webサーバ)からホームページを見るときに使うソフト(Webブラウザ)に対して、ホームページのファイルが渡されます。
このとき、ホームページのファイルには「このファイルは、こんな種類のファイルですよ」な情報がくっついています。
例えば「HTMLファイルですよ」や「画像です」などです。
23行目:
params = {'visualFeatures': 'Description'}
Computer Vision APIに渡すパラメーターを指定します。
'visualFeatures'に、Computer Vision APIの解析から得たい画像の情報の種類を指定します。
どのような画像の情報を得られるか?は下記のURLのRequest parametersを参照して下さい。
今回は「画像の説明(=Description)」のテキストを画像ファイル名のリネームに使用したいので
'Description'と指定しました。
もし複数の種別を指定したい場合は
'Categories, Description, Color'のようにカンマで区切って指定します。
24行目:
img = open(filepath, 'rb')
第1引数のfilepathに指定されているJPEG画像ファイルをオープンしています。
オープンしたファイルオブジェクトが変数imgに代入されます。
第2引数の'rb'は、リードバイナリというオープンモードを示しています。
1文字目の「r」はreadの頭文字で、ファイルを読み取り形式でオープンするという意味になります。
書き込み形式でオープンする場合は、writeの「w」になります。
2文字目の「b」はバイナリモードという意味です。
これが付いてない場合はテキストモードでオープンするという意味になります。
今回はテキストファイルではなく画像ファイルを扱うので「r」の後ろに「b」を付けます。
25行目:
img_byte = img.read()
リードバイナリモードでオープンした画像ファイルオブジェクトを読み込み、変数img_byteに格納しています。
26行目:
response = requests.post(analyze_url, data=img_byte, headers=headers, params=params)
Computer Vision APIにリクエストを送信し、返ってきた解析結果を変数responseに格納しています。
4つの引数については、それぞれ以下のように指定されています。
analyze_url=Computer Vision APIのURLdata=解析したいJPEG画像ファイルheaders=リクエストヘッダーparams=解析させたい情報種別27行目:
response.raise_for_status()
APIから返ってきたレスポンスにエラーがないかチェックしています。
もしエラーがあればエラーメッセージを出力した後にプログラムが強制終了するようになっています。
28行目:
return response.json()
response.json()でAPIから返ってきたレスポンスをJSON形式に変換しています。
変換されたJSON形式のデータは、ms_computer_vision_api関数の呼び出し元(36行目)に渡されます。
直接プログラムを実行しているかチェック
29行目:
if __name__ == "__main__":
このPythonプログラムが直接実行されているかを判定しています。
cv_demo.pyを直接実行した場合、__name__には”__main__”という値が代入されるようになっています。
この場合のみ、if文がTrueとなるので、この下に続く処理が実行されます。
画像ファイルを配列に格納
30~33行目:
# 画像ファイルを配列に格納
image_file = glob.glob('./img/*')
vision_file_name = []
start = time.time()
31行目:
image_file = glob.glob('./img/*')
imgフォルダにあるファイルパス名を全て取得しリストにしたものを、image_fileという変数に格納します。
32行目:
vision_file_name = []
vision_file_nameという名前の空のリストを準備します。
33行目:
start = time.time()
システムの時刻を取得して変数startに格納しています。これがプログラムの実行開始時刻になります。
プログラムの終了時に表示する「実行にかかった時間」を算出するのに使います。
Computer Vision APIにリクエストして解析結果を取得
34~36行目:
# Computer Vision APIにリクエストして解析結果を取得
for i in range(len(image_file)):
json_data = ms_computer_vision_api(image_file[i])
35行目:
for i in range(len(image_file)):
range(len(image_file))は、0から「image_fileの要素数-1」までの値が格納されたリスト。
このリストの値をfor文で1つずつ変数iに取り出し、image_fileのインデックスとして使います。
36行目:
json_data = ms_computer_vision_api(image_file[i])
ms_computer_vision_api関数を呼び出して、image_file[i]の解析処理を実行します。
APIから返ってきた解析結果を、json_dataという変数に格納しています。
解析結果のテキストを取得
37~39行目:
# 解析結果のテキストを取得 file_name = json_data['description']['captions'][0]['text'] vision_file_name.append(file_name)
38行目:
file_name = json_data['description']['captions'][0]['text']
JSON形式で取得したデータは第1・第2階層が辞書形式になってますので
json_data['description']['captions']
で第1キーが’description’、第2キーが’captions’でアクセスします。
第3階層は要素が1つだけのリスト形式になってますので
json_data['description']['captions'][0]
でインデックスが0の要素にアクセスします。
第4階層は再び辞書形式になってますので
json_data['description']['captions'][0]['text']
で目的の要素のキーである’text’を指定して解析結果のテキストを取り出し、変数file_nameに格納します。
39行目:
vision_file_name.append(file_name)
32行目で作成したvision_file_nameリストに、変数file_nameを追加します。
文章の空白をファイル名用にアンダーバーに変換
40~42行目:
# 文章の空白をファイル名用にアンダーバーに変換
for i in range(len(vision_file_name)):
vision_file_name[i] = vision_file_name[i].replace(' ', '_')
解析結果から取り出したテキストには、単語と単語の間にスペースが入っています。
ファイル名に空白(スペース)があると、エラーが生じやすくなってしまいます。
なぜなら、スペースが文字としての空白なのか、コマンドの区切りなのか、区別がつかないからです。
ですので、空白をアンダーバーに置き換えてエラーを回避しています。
41行目:
for i in range(len(vision_file_name)):
range(len(vision_file_name))は、0から「vision_file_nameリストの要素数-1」までの値が格納されたリスト。
このリストの値をfor文で1つずつ変数iに取り出し、vision_file_nameのインデックスとして使います。
42行目:
vision_file_name[i] = vision_file_name[i].replace(' ', '_')
文字列を置換する関数replace(' ', '_')によって、空白をアンダーバーに置き換えます。
よって、vision_file_name[i]にある空白がアンダーバーに置き換えられます。
そして置き換えられた後の値が、vision_file_name[i]に代入されます。
変換後のテキストで画像ファイルをリネーム
43~44行目:
# リネーム処理 file_rename(image_file, vision_file_name)
file_rename関数を呼び出し、image_fileとvision_file_nameを引数にしてリネーム処理を実行します。
具体的には、imgフォルダにある全ての画像ファイルを、以下のような名前にリネームします。
プログラムの最後に経過時間を出力
45~46行目:
# 経過時間を出力
print("elapsed_time:{}".format(time.time() - start) + "[sec]")
最後に、このプログラムの処理にかかった時間を出力します。
time.time() - startは以下のようになるので、経過時間を算出できます。
そして、この計算結果をformat関数で
"elapsed_time:{}"の{}部分に埋め込みます。


コメント