
「機械学習」(Machine learning、略してML)とは何でしょうか?
ざっくり言うと、「コンピューターを使って、人間の脳のような学習能力を再現しよう」という技術です。
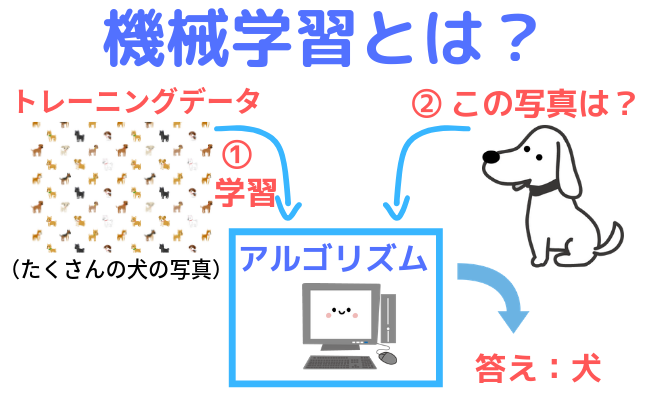
機械学習では、コンピューターのアルゴリズムにあらかじめまとまった数のデータ(トレーニングデータ)を与えることによってデータを学習させ、アルゴリズムによる画像の認識や、未来に起こる事柄のデータの予想などを可能にしてくれます。
次からは、機械学習についてもっと深く掘り下げていきます。
今回は機械学習について簡単に解説していくよ
難しそうだね
簡単に解説していくから大丈夫だよ
機械学習とディープラーニングの違い

人間よりも精度が高いってすごいね
そうだね。次からは機械学習で主にできることを解説していくよ。
機械学習は教師あり学習と教師なし学習、強化学習の3つに分かれる
機械学習には、大きく分けて教師あり学習と、教師なし学習と強化学習の3つに分けられます。
まずは教師あり学習から紹介するよ
教師あり学習はいくつかの特徴量のデータとセットになった正解データをまずアルゴリズムに学習させて、その学習モデルを使って正解が分かっていないデータを予測したり、分類したりする方法です。
教師あり学習で代表的なものとしては「分類」、「回帰」があります。
分類、回帰について詳しく見ていきます。
与えられたデータを分ける『分類』
まず1つ目が『分類』です。
読んで字の如く、文字通りの仕分け作業です。
分類では、データからパターンを学習して、何に分類できるのかを判断してくれます。
たとえば下の図のようにコンピューターにレモンとリンゴの画像を与えれば、データの特徴を調べて、コンピューターは「レモン=黄色い」や「リンゴ=赤い」といった特徴のパターンを覚えます。

すると次第に、新しくレモンの画像を与えても、そのデータの特徴(画素など)を見て、
リンゴではなくレモンだと自分で判定できるようになるのです。

このように色や形などの複数の特徴からあるデータを分類してくれるのが機械学習の『分類』になります。
未来のデータを予測する『回帰』
3つ目は未知のデータを予測する『回帰』というもの。
回帰では、これまでのデータを参考に、これからの結果を予測します。
この回帰による機械学習は天気予報や株価予測などにも使われています。
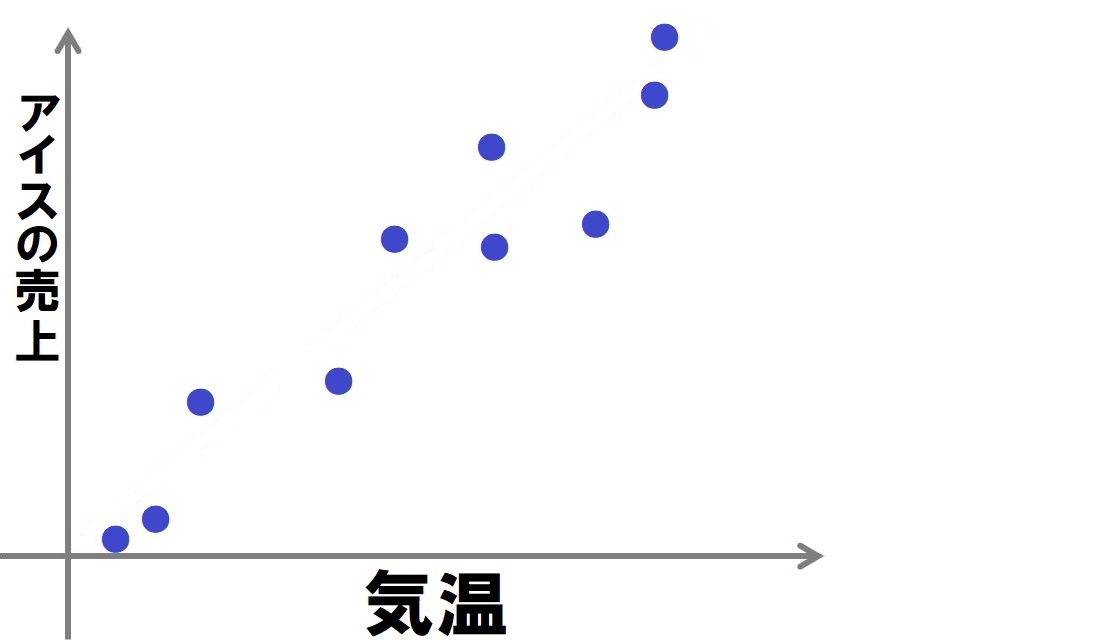
たとえば、過去の気温データとアイスの売上データを与えれば、
コンピューターは2つの数値がどのような比例関係にあるかのパターンを学習します。
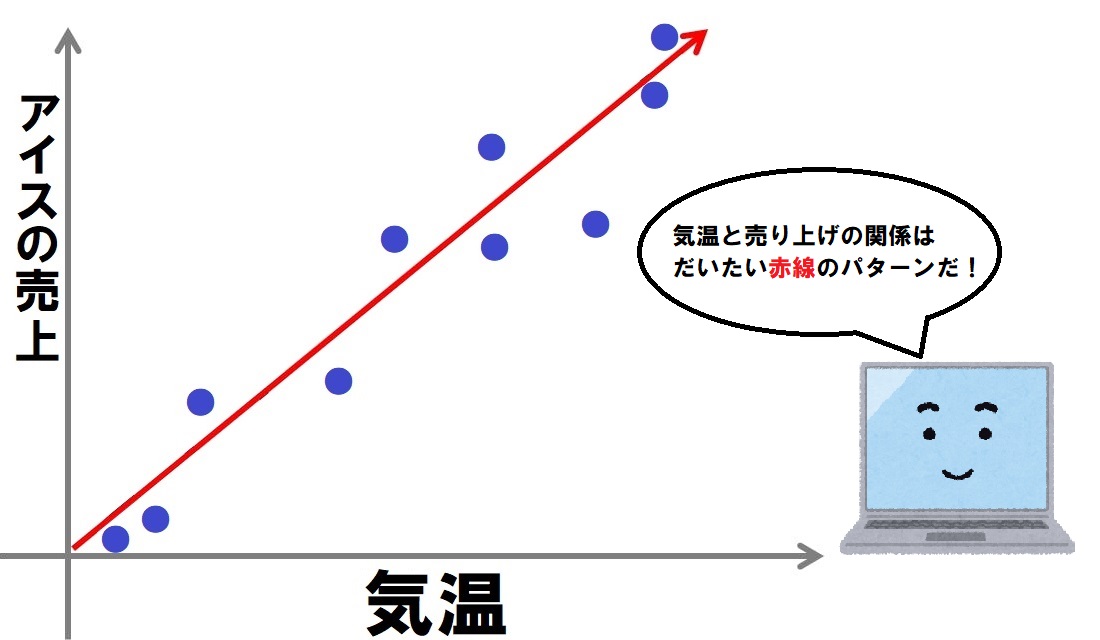
パターンに従って、どのような関係のモデル(赤線部分)を見つけます。
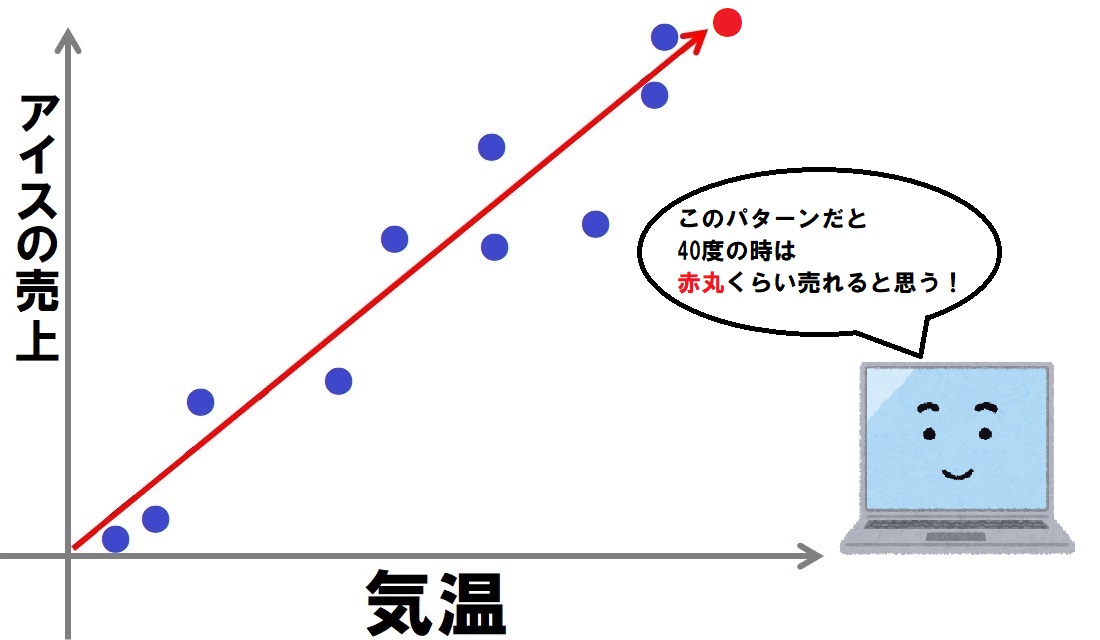
モデルを参考にすることで、データにない気温や売上であっても、
コンピューターはその数値を予想することができるようになるのです。
パターンから別のデータを提案する『推薦』
4つ目は『推薦』です。
推薦では、データからパターンを見つけだして、別の関連情報を導いてくれます。
この機械学習による推薦は、Amazonの「この商品を見たお客様はこれも見ています」というレコメンド機能に使われています。
ユーザーの購入履歴から、コンピューターが傾向を見つけだして、別の商品をオススメしているのです。
下の図を見て下さい。Aくんを見ると、「うどんが好き」かつ「そばが好き」というデータがあります。
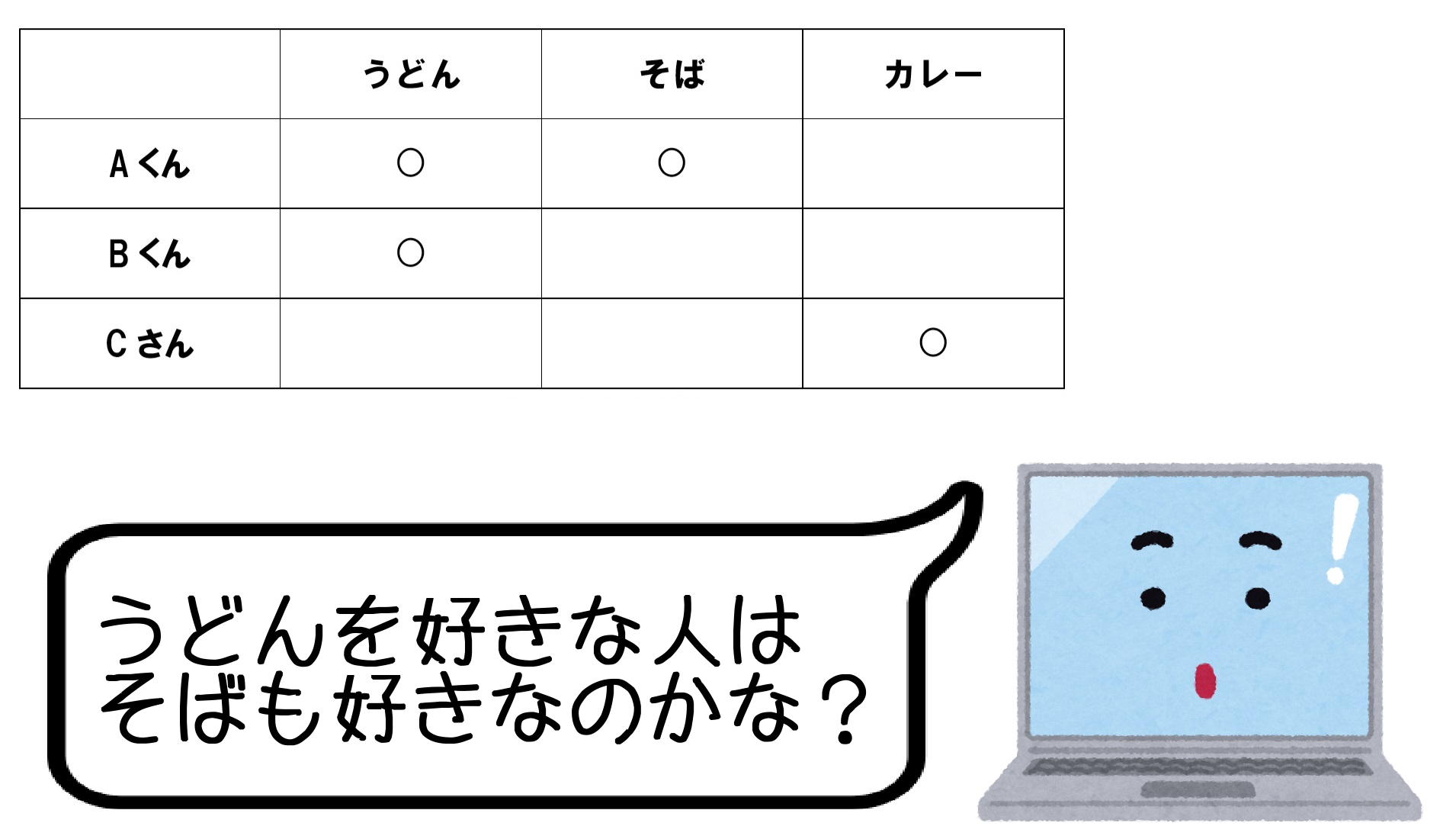
そこからコンピューターは「うどんが好きな人はそばも好き」というモデルを考えます。

この例では3名分のデータで説明したため、パターンは1つしか見つかりませんでした。
しかし実際のデータは何千や何万単位なので、より多くのパターンが見受けられます。
教師なし学習とは
次は教師なし学習について紹介します。
教師なし学習は正解データが与えられておらず、学習データのみで学習して、正解を見つけていく学習方法となります。
『クラスタリング』
2つ目は『クラスタリング』というもの。
データから似たような集まりを見つけて、自動でグループ分けします。

クラスタリングは単純に似ているデータを集めて区分けしています。

『分類』と『クラスタリング』の違い
分類もクラスタリングも同じくデータを分けますが、仕組みはまったくの別物です。
いろいろな果物がまとめられたデータがあり、そこからレモンを分けたとします。
『分類』は画像+名前のセットで、「レモン」というパターンを認識させていきます。
あらかじめ決められたルールに沿って、データを整理していくのです。
一方で『クラスタリング』はルールがなくても、コンピューターが自己判断で似たデータ同士に分けます。
しかしこの「自己判断」で、似たデータをまとめるという部分が落とし穴です。
コンピューターの判断によっては、レモンとバナナが「黄色いもの」で一括りになってしまうかもしれないのです。
どう分けるのか決まっているのが『分類』、ただ似た者同士を集めるだけが『クラスタリング』と覚えてください。
データの主旨はそのまま省略する『次元削減』
5つ目は『次元削減』です。
次元削減ではデータの特徴は残しつつ、不要な次元を削減します。
例えば、テストで各教科の得点を、総合点として1つに集約することも次元削減の1つです。
主にデータの圧縮などを目的として、次元削減は行われます。
大きな次元のデータを処理する場合、次元を削減すれば、データを処理する計算時間も短縮できます。
下の図は、身長と体重のデータを8人分あつめた図です。
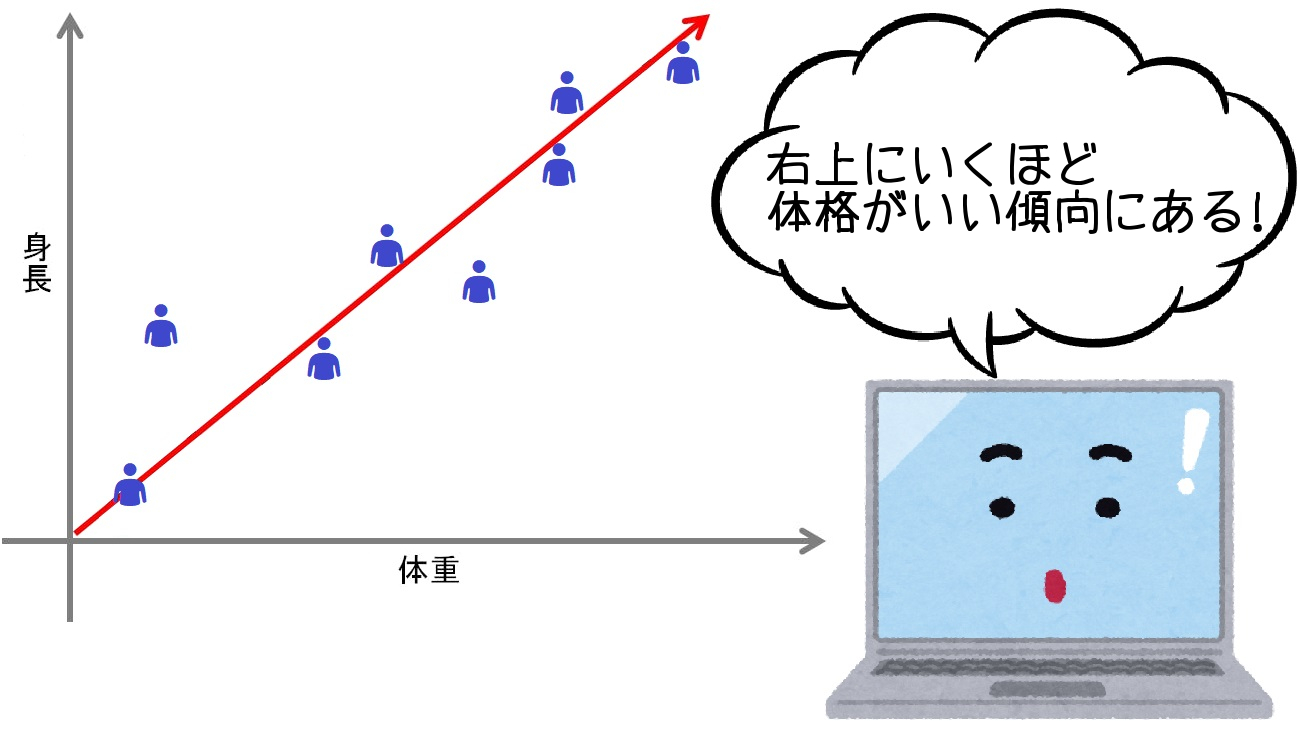
赤線のように、右上にいくにつれて体格がよい傾向に気付きます。
ということで、下の図のように体格だけのデータをつくりました。
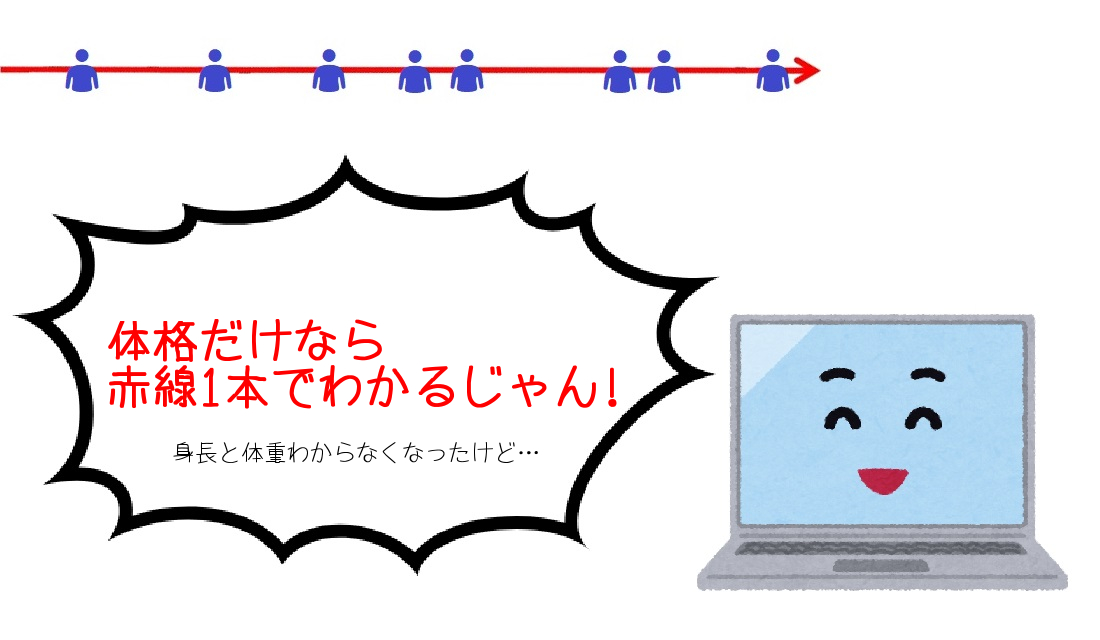
2次元から1次元に減らしていますが、削減後もデータの意味は果たしています。
ただし、少なからず元のデータが失われていることには注意しましょう。
体格のデータであって、身長と体重の数値はわからなくなってしまいました。
2次元→1次元の例で説明したのでイマイチ伝わらないかもしれませんが、
実際には10000次元→100次元のような圧縮をするので、有用性は段違いになります。
ここまでは大丈夫?
すんなり理解できたよ
よかった!じゃあ次は機械学習の学習方法の3分類をもう少し詳しく見ていくね
機械学習の学習方法をもっと詳しく
機械学習の「学習」とは、具体的に何なのでしょう?
それは「データからパターンを見つける」ことです。
コンピューターはデータを何度も計算して、学習を繰り返します。
繰り返すことで、データに隠れているパターンを探しているのです。
このような機械学習の学習方法には、大きく分けて3種類あります。
データ+答えのセットで学習する『教師あり学習』
『教師あり学習』は、例題を見ながら勉強するイメージです。
『分類』や『回帰』や『推薦』などが、教師あり学習で実現できます。
コンピューターに与えるのは、データ+ラベルのセットです。
この「ラベル」はデータに関する情報、すなわち答えのようなものです。
データ+ラベルを例題のようにコンピューターが学習して、対処マニュアルのような「モデル」を作ります。

モデルを参考にすることで、コンピューターは未知のデータに対しても、例題と同じように処理する事ができるのです。

例えば、コンピューターがひまわりの画像を認識できるようにしてみましょう。
「ひまわりの花びらは、黄色だよ」
「ひまわりの真ん中は、茶色だよ」
このように人間がラベルを与える(=教えてあげる)必要があるのです。
答えのないデータのみで試行錯誤する『教師なし学習』
『教師なし学習』は、模範解答なしで勉強するイメージです。
『クラスタリング』や『次元削減』が、教師なし学習で実現できます。
コンピューターにはラベルを与えずに、データだけを与えます。
しかしラベル(答え)がない以上、『教師あり学習』と違って正解も不正解もわかりません。

そこで困ったコンピューターは、データに隠れているパターン(類似性など)を自分で見つけだして、グループ分けなどの処理を行うのです。

しかし、コンピューター自身は似たようなデータを集めるだけで、それが何の集まりであるかなどは人間がラベル付けする必要があるので注意しましょう。
この時点でも、コンピューターはこの画像が「ひまわり」であることはもちろん、
「黄色」と「赤色」を基準に花をクラスタリングしたことを自覚していません。
与えられたゴールへの最善策を探す『強化学習』
『強化学習』は、ゴールだけ決めて勉強するイメージです。
コンピューターにラベルは与えませんが、データと達成させたい目標を与えます。
『教師なし学習』と同様にラベルが与えられていないので、答えがわからない状態ですね。

するとコンピューターは目標を達成するために「何をすれば、どうなるか」をフィードバックしていきます。
この画像に「チューリップ」と答えても、報酬は得られない(=目標に近づけない)ことを覚えました。

この画像に「ひまわり」と答えると、報酬が得られる(=目標に近づく)ことを覚えました。
この時点で、コンピューターは報酬を得る事のできるパターンを学習した事になります。

そうしてトライ&エラーを繰り返して学習したコンピューターは、ベストな選択肢を選べるようになるのです。
ここまでが機械学習の基礎になるので、それぞれの単語の意味をしっかりと理解して覚えておきましょう。

コメント