Pythonのプログラムを書く時のテクニックとして、正規表現という文字列の表現方法があります。
正規表現を使うと、特定のパターンを持つ文字列を一般的に表現することができます。
この正規表現を使えば、ある特定の文字列を文章の中から見つけたりする時に便利です。
正規表現は一度理解してしまえばとても便利に使えるので、絶対に覚えておいて損はありません。
正規表現ならシンプルに表記できる
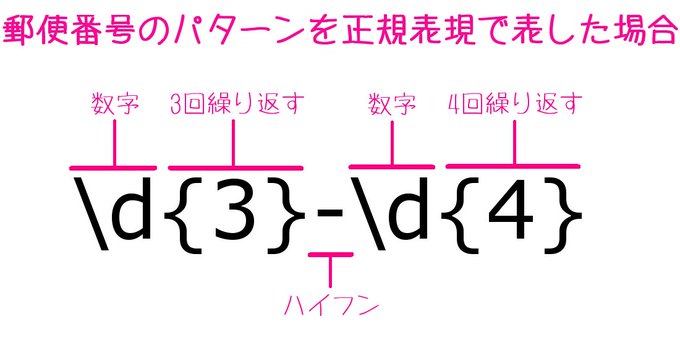
わかりやすい例として、郵便番号について考えてみます。
郵便番号は000-0000のように、3ケタの数→ハイフン→4ケタの数というパターンですね。
これをプログラム言語で書こうとすると、0〜999の数字→ハイフン→0〜9999の数字…などと書かなければいけなくて意外と面倒です。
正規表現なら、\d{3}-\d{4}だけで表現できてしまいます。
よく使う正規表現を一覧で解説
正規表現は文字列のパターンを記号で表す文字列になります。
その正規表現の特殊文字のことをメタ文字と言います。
具体的には*とか、+とか、?みたいなものです。
はじめは基本中の基本、よく使う位置・回数・内容3パターンの正規表現のメタ文字だけ覚えておけばOKです。
マッチする位置を表す正規表現
位置を表現できる正規表現です。
| ^ | 文字列の先頭を表します。 \Aと同じ |
| $ | 文字列の末尾を表します。 \Zと同じ |
マッチする回数を表す正規表現
パターンを繰り返す回数を表す正規表現です。
| * | 直前の文字を0回以上繰り返したものを表します |
| + | 直前の文字を1回以上繰り返したものを表します |
| ? | 直前の文字を0回または1回繰り返したものを表します |
| {x} | 直前の文字をちょうどx回繰り返したものを表します |
| {x,y} | 直前の文字をx回以上y回以下の範囲で繰り返したものを表します |
例
abc* は ab, abc, abcc, abccccなどを表します。
ab+cは abc, abbc, abbbcなどを表します。
ac?dは ad, acd を表します。
ab{3}は abbb を表します。
マッチする内容を表す正規表現
文字列の内容を表す正規表現です。
| . | 改行以外の任意の1文字を表します |
| [] | []内のいずれか1文字を表します |
| [^~] | ~に含まれない1文字を表します |
| | | A|BでAまたはBを表します |
| \d | 任意の数字1文字を表します。 [0-9]と同じ |
| \D | 任意の数字以外の1文字を表します。 [^0-9]と同じ |
| \s | 空白文字を表します |
| [a-z] | アルファベットのa~zのうちの1文字 |
|
[a-zA-Z] |
アルファベットのa~z,A~Zのうちの1文字 |
| \w | 英数文字またはアンダースコアのうちの任意の1文字を表します。 [a-zA-Z0-9_]と同じ |
例
a.c は abc, a1c, azcなどを表します。abbcは一致しません。
[a13bd] は a, 1, 3, b, dのうちのいずれか1文字を表します。
a\d@ は a3@, a5@, a0@ などを表します。
ac\wd は acZd, ac1d, acwdなどを表します。
任意の長さの文字列にマッチさせたい場合
任意の長さの文字列、例えばa1>354などを表す正規表現は
.* や .+ です。
最長一致と最短一致
.*や.+は任意の長さの文字列にマッチしますが、どちらも最長一致です。
最長一致とは?
最長一致はできるだけ最長となるようにマッチするという意味です。
具体例をあげた方が分かりやすいので具体例を挙げます。
例えば、 <div>abx23<h1>今日の天気</h1>は晴れです。</div>
という文字列があった場合、<div>や<h1>にマッチさせる正規表現として <.*>や <.+>
が考えられそうですが、実際には <.*> を使うと
最短一致とは?
.*? や .+? を最短一致と言います。
最短一致とは、できるだけ短い文字列となるようにマッチするという意味です。
ただ、ここで気をつけておきたいことが、.*? や .+? はどちらも最左最短一致であるということです。
どういうことかを具体的な正規表現を例に挙げて見ていきます。
例えば、 <div>abx23<h1>今日の天気</h1>は晴れです。</div> の
<h1> にマッチさせたいとします。
そういう時には最短一致を使って、 <.*?\d> でマッチさせられそうですが、
実際には、 <.*?\d> だと <div>abx23<h1> がマッチしてしまいます。なぜなら、.*?自体は最左最短一致だからです。
最左最短一致とは、「最も左まで一致するものを探してから、最短一致させる」という意味です。
しかも、最左一致の方が優先度は高いんです。だから<h1>にマッチさせたい場合は <[^/<]*?\d> と書きます。
[^/<]の部分は/や<ではない文字列(.の任意の文字列から、/や<を除いた文字列)となります。
/は</h1>にマッチしない為に入れています。
このように、最短一致を使う際には気をつけて下さい。
正規表現のメタ文字をエスケープできるバックスラッシュ
正規表現パターンで使うメタ文字を普通の文字列として扱いたい場合、\ を直前に置きます。
| \ | 直後の正規表現の特殊文字1文字をエスケープ(直後の文字を正規表現のメタ文字として扱わないことを表す) |
たとえば「+」は正規表現だと「直前の正規表現の1回以上の繰り返し」という意味になります。
これを正規表現ではない普通の文字列として扱いたい場合、「\+」と記述します。
正規表現がマッチするかチェックするreモジュール
Pythonで実際に正規表現のパターンに当てはまるかチェックするにはreモジュールを使います。
Pythonではreモジュールを使うことで、さまざまな条件でチェックすることができます。
reモジュールの使い方は2種類
reモジュールの使い方は2種類あります。一つは「re.compileを使って正規表現パターンをコンパイルして、正規表現パターンオブジェクトを作り、そのメソッドを使う」方法。
もう一つはre.search()やre.match()などの「関数を使って正規表現を扱っていく方法」のどちらかです。
re.compileで正規表現パターンをコンパイルする
上でも述べたようにreモジュールの使い方は実は2通りあって、
re.match()などのように関数を使う方法と、
re.compile(正規表現)として、まず正規表現パターンをコンパイルして正規表現オブジェクトとして取得し、その正規表現オブジェクトのメソッドとして、matchやsearchを使う方法があります。
reg = re.compile(r'\w+@[a-z]+\.com')
output = reg.search('abc@gmail.com, abc@343.com, ddc@542.com')
print(output)
#出力結果 <re.Match object; span=(0, 13), match='abc@gmail.com'>
re.compileを使うメリット
上記のように、最初に正規表現パターンのr'\w+@[a-z]+\.com'をre.compile()によってコンパイルすることによって同じ正規表現パターンをコードの中で繰り返し使う場合に楽です。
また、処理速度もコンパイルしない場合よりも早くなります。
ただ、特に繰り返し使う正規表現がない場合は無理にコンパイルする必要はありません。
マッチしているかチェックする関数
| re.match(パターン, 文字列) | 文字列の先頭がパターンにマッチ |
| re.search(パターン, 文字列) | 文字列の一部がパターンにマッチ |
| re.fullmatch(パターン, 文字列) | 文字列の全体がパターンにマッチ |
返り値はすべてmatchオブジェクトになります。(matchオブジェクトとは、チェックした結果の情報のこと。文字列ではない点に注意)
具体例を見ていきましょう。
文字列の先頭だけチェックするre.match()
re.match()で、パターンにマッチするかチェックします。
ただしチェックするのは文字列の先頭だけです。
例.
text = 'uuyr112@gmail.com, uuyr112@yahoo.co.jp, uuyr112@icloud.com' match = re.match(r'\w+@[a-z]+\.com', text) print(match) #出力結果 <re.Match object; span=(0, 17), match='uuyr112@gmail.com'>
3行目において、.は特殊文字なので、\.としてエスケープしています。
今回の場合、uuyr112@icloud.comも正規表現のパターンに当てはまるのですが、re.matchが探すのは文字列の先頭でのマッチ。
uuyr112@icloud.comは文字列の先頭にはないのでマッチしません。
文字列全体をすべてチェックするre.search()
re.search()で、パターンにマッチするかチェックします。
先頭だけでなく文字列全体もチェックしてくれます。
例.
text = 'uuyr112@gmail.com, uuyr112@yahoo.co.jp, uuyr112@icloud.com' match = re.search(r'\w+@[a-z]+\.co.jp', text) print(match) #出力結果 <re.Match object; span=(19, 38), match='uuyr112@yahoo.co.jp'>
文字列すべてが完全一致するかチェックするre.fullmatch()
re.fullmatch()で、正規表現パターンにマッチするかチェックします。
文字列全体をチェックしますが、文字列全てがマッチしないと無効です。
例.
text = 'uuyr112@gmail.com' match = re.fullmatch(r'\w+@[a-z]+\.com', text) print(match) #出力結果 <re.Match object; span=(0, 17), match='uuyr112@gmail.com'>
文字列の一部がマッチしていても、None扱いされてしまいます。
text = 'uuyr112@gmail.com, uuyr112@yahoo.co.jp, uuyr112@icloud.com' match = re.fullmatch(r'\w+@[a-z]+\.com', text) print(match) #出力結果 None
マッチしている部分を全て取り出してリストやイテレータとして返す関数
| re.findall(パターン, 文字列) | マッチ部分をすべて取得してリストとして返す |
| re.finditer(パターン, 文字列) | マッチ部分をすべて取得してイテレータとして返す |
マッチした部分の文字列を全て取得してリストとして返すre.findall()
re.findall()では、パターンにマッチする部分をすべて抽出します。
返り値はリスト型で、マッチ部分の文字列をまとめたリストで返します。
例.
text = 'uuyr112@gmail.com, uuyr112@yahoo.co.jp, uuyr112@icloud.com' result = re.findall(r'\w+@[a-z]+\.[a-z]+', text) print(result) #出力結果 ['uuyr112@gmail.com', 'uuyr112@yahoo.co', 'uuyr112@icloud.com']
マッチした部分を全て取得して、matchオブジェクトとして返すre.finditer()
re.finditer()でも、パターンにマッチする部分をすべて抽出します。
ただし返り値はイテレータで、matchオブジェクトの集合体になります。
例.
text = 'uuyr112@gmail.com, uuyr112@yahoo.co.jp, uuyr112@icloud.com' result = re.finditer(r'\w+@[a-z]+\.[a-z]+', text) print(result) #出力結果 <callable_iterator object at 0x10b0efa90>
イテレータをfor文などで取り出すことで、matchオブジェクトを1つずつ取得できます。
for match in result:
print(match)
#出力結果 <re.Match object; span=(0, 17), match='uuyr112@gmail.com'>
#出力結果 <re.Match object; span=(19, 35), match='uuyr112@yahoo.co'>
#出力結果 <re.Match object; span=(40, 58), match='uuyr112@icloud.com'>
マッチしている文字列を操作する関数
| re.sub(パターン, 置換後の文字列, 文字列) | マッチした部分を他の文字列に置換 |
| re.split(パターン, 文字列) | マッチした部分で文字列を分割 |
マッチした部分の文字列を置換するre.sub()
re.sub()は、マッチした部分を他の文字列に置き換えます。
返り値は文字列で、置き換えた後の文字列が返ってきます。
例.
text = 'uuyr112@gmail.com' result = re.sub(r'\w+@[a-z]+\.com', 'address', text) print(result) #出力結果 address
マッチした部分で文字列を分割するre.split()
re.split()は、マッチした部分で文字列を分割します。
返り値はリスト型で、分割した文字列をまとめたリストが返ってきます。
例.
text = 'uuyr112@gmail.com'
result = re.split('[0-9]+', text)
print(result)
#出力結果 ['uuyr', '@gmail.com']
matchオブジェクトからマッチした情報を取り出す
re.match()やre.search()などでは返り値として、matchオブジェクトが取得できます。
matchオブジェクトはメソッドを使って、正規表現パターンにマッチした部分の情報を取り出すことができます。
その具体的な方法について紹介していきます。
マッチした位置を取得する
matchオブジェクト.start()では、マッチした部分の開始位置を取得できます。
matchオブジェクト.end()では、マッチした部分の終了位置が取得できます。
matchオブジェクト.span()では、マッチした部分の開始位置・終了位置のタプル型が取得できます。
例.
text = 'uuyr112@gmail.com'
match = re.match(r'\w+@[a-z]+\.[a-z]+', text)
print(match.start()) #出力結果 0 print(match.end()) #出力結果 17 print(match.span()) #出力結果 (0,17)
マッチした文字列を取得
re.match()やre.search()では返り値がマッチオブジェクトとして
<re.Match object; span=(0, 17), match=’uuyr112@gmail.com’>
のような形で返されてました。
ここでマッチオブジェクトではなく、正規表現にマッチしたuuyr112@gmail.comの文字列を得る方法について紹介します。
matchオブジェクト.group()
で、マッチオブジェクトから文字列を取得できます。
例.
text = 'uuyr112@gmail.com' match = re.match(r'\w+@[a-z]+\.[a-z]+', text) print(match.group()) #出力結果 uuyr112@gmail.com
正規表現のグルーピング(キャプチャ)とグループの取得
正規表現は一部分を()で囲むことによって1つのグループとすることができ、番号で呼び出したり、その部分だけ取り出すことができるので便利です。
この()をつけてグルーピングする操作をキャプチャとも言います。
例えば下の例だと、\d+が1番目のグループ、\D*が2番目のグループ、[0-9]が3番目のグループという形で前から順番に番号がふられます。
(\d+)-(\D*)-([0-9])
group()の引数にそれらの数字を入れるとそれぞれのグループ単位で文字列を取り出すことができます。
例.
r = re.compile("(\d+)-(\D*)-([0-9]+)")
m = r.search("145-Mfre-473")
print(m.group(1))
#出力結果
145
print(m.group(2))
#出力結果
Mfre
print(m.group(3))
#出力結果
473
ちなみに引数を入れない形のgroup()で取得できるのはマッチした部分の全体になります
各グループのマッチした文字列をタプルで取得
正規表現パターンを()でグループ分けした場合、
マッチオブジェクト.groups()
を使うことで、各グループのマッチした文字列を全てタプルとして取得できます。
groups()となってsがつくことに注意して下さい。
例.
text = 'uuyr112@gmail.com'
match = re.match(r'(\w+)@([a-z]+)\.([a-z]+)', text)
print(match.groups())
#出力結果 ('uuyr112', 'gmail', 'com')
このようにgroups()を使うと、文字列のキャプチャされた部分をタプルとして一気に取得できます。
reモジュールを扱ったPythonのプログラム例の記事
下記はreモジュールをプログラム内で使ってあるPythonのプログラムの解説記事になります。



コメント