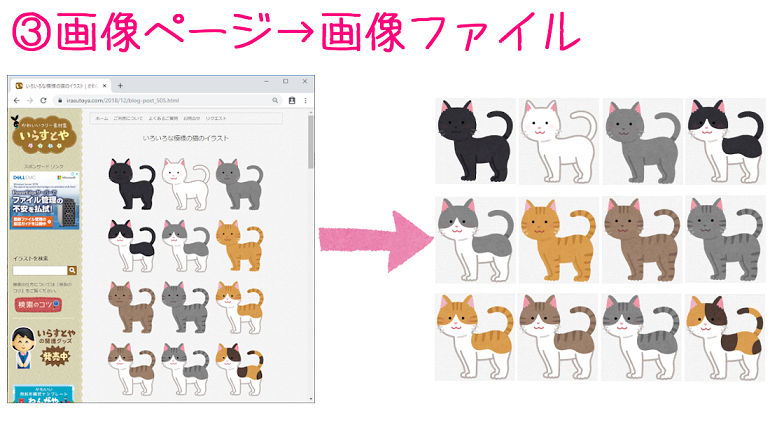
Pythonでスクレイピングを一番使うのが、画像を集める時です。
今回は「いらすとや」のURLを渡すだけで、検索結果にある画像をすべて自動でダウンロードしてくれるプログラムです。
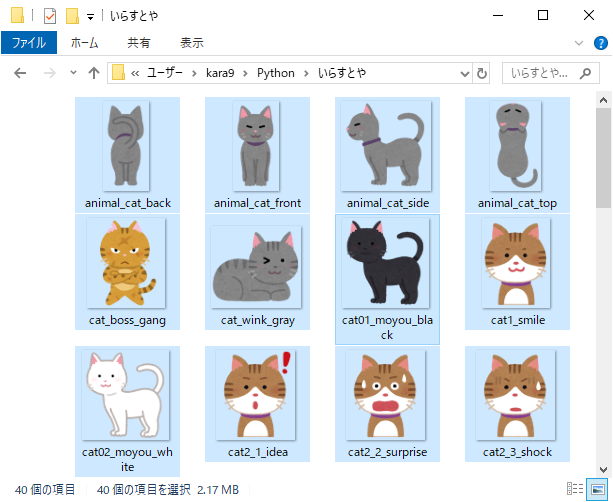
プログラムを実行するだけで、画像が一気にダウンロードされていきます。
いちいちページに飛んで右クリック保存…という面倒な作業を丸投げできるので、作業時間を短縮することができます。
プログラムのソースコード
#●画像ファイルをダウンロードするための準備
# ①-①.ライブラリをインポート
import time
import re
import requests
from pathlib import Path
from bs4 import BeautifulSoup
# ①-②.出力フォルダを作成
output_folder = Path('いらすとや')
output_folder.mkdir(exist_ok=True)
# ①-③.スクレイピングしたいURLを設定
url = 'https://www.irasutoya.com/search?q=%E7%8C%AB'
# ①-④.画像ページのURLを格納するリストを用意
linklist = []
#●検索結果ページから画像のリンクを取り出す
# ②-①.検索結果ページのhtmlを取得
html = requests.get(url).text
# ②-②.検索結果ページのオブジェクトを作成
soup = BeautifulSoup(html, 'lxml')
# ②-③.画像リンクのタグをすべて取得
a_list =soup.select('div.boxmeta.clearfix > h2 > a')
# ②-④.画像リンクを1つずつ取り出す
for a in a_list:
# ②-⑤.画像ページのURLを抽出
link_url = a.attrs['href']
# ②-⑥.画像ページのURLをリストに追加
linklist.append(link_url)
time.sleep(1.0)
# ●各画像ページから画像ファイルのURLを特定
# ③-①.画像ページのURLを1つずつ取り出す
for page_url in linklist:
# ③-②.画像ページのhtmlを取得
page_html = requests.get(page_url).text
# ③-③.画像ページのオブジェクトを作成
page_soup = BeautifulSoup(page_html, "lxml")
# ③-④.画像ファイルのタグをすべて取得
img_list = page_soup.select('div.entry > div > a > img')
# ③-⑤.imgタグを1つずつ取り出す
for img in img_list:
# ③-⑥.画像ファイルのURLを抽出
img_url = (img.attrs['src'])
# ③-⑦.画像ファイルの名前を抽出
filename = re.search(".*\/(.*png|.*jpg)$",img_url)
# ③-⑧.保存先のファイルパスを生成
save_path = output_folder.joinpath(filename.group(1))
time.sleep(1.0)
# ●画像ファイルのURLからデータをダウンロード
try:
# ④-①.画像ファイルのURLからデータを取得
image = requests.get(img_url)
# ④-②.保存先のファイルパスにデータを保存
open(save_path, 'wb').write(image.content)
# ④-③.保存したファイル名を表示
print(save_path)
time.sleep(1.0)
except ValueError:
# ④-④.失敗した場合はエラー表示
print("ValueError!")
ソースコードの詳細な解説
ここからはソースコードを1行ずつ解説していきます。
はじめのブロックは、画像を保存するための準備作業です。
ここではダウンロードしたいURLを設定したり、画像を保存するためのフォルダを用意したりしています。
プログラムで使うライブラリをimport
3~6行目:
import re import requests from pathlib import Path from bs4 import BeautifulSoup
プログラムを動かすために必要な4つのライブラリをimportします。
- BeautifulSoupライブラリ…画像を探す時、htmlの検索に使います
- requestsモジュール…Webページの読み込みに使います
- reモジュール…画像を探す時、文字列の検索に使います
- Pathlibモジュール…画像を保存する時、ファイルパスの操作に使います
出力先のフォルダを作成
8~9行目:
output_folder = Path('いらすとや')
output_folder.mkdir(exist_ok=True)
pathlib.path('いらすとや')で、「いらすとや」というフォルダ名のPathオブジェクトを作成して、変数output_folderとします。
mkdir()では、Pathオブジェクト(変数output_folder)から「いらすとや」フォルダを作成します。
この時、(exist_ok=True)で同じ名前のフォルダが既にあってもエラーが起きないように指定しています。
スクレイピングしたいURLを設定
11行目:
url = 'https://www.irasutoya.com/search?q=%E7%8C%AB'
画像をダウンロードしたいページのURLを、変数urlに設定します。
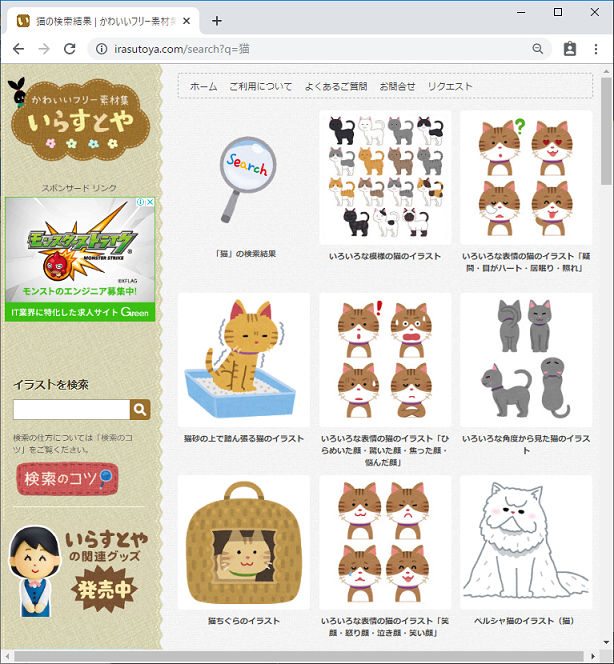
今回は「いらすとや」で「猫」と検索した時の検索結果ページのURLを指定しました。
この部分に「いらすとや」の他の検索結果を入れてもスクレイピングできるので、ぜひ試してみてください。
空のリストを用意
13行目:
linklist = []
変数linklistとして、空のリストを作成します。
この時点では空っぽですが、あとで検索結果ページから画像ページのリンクを取り出して、このリストに格納していきます。
これでスクレイピングを始めるための準備ができました。
検索結果から各画像ページのリンクを取り出す
2番目のブロックでは、検索結果のページから各画像のURLを全て取り出します。
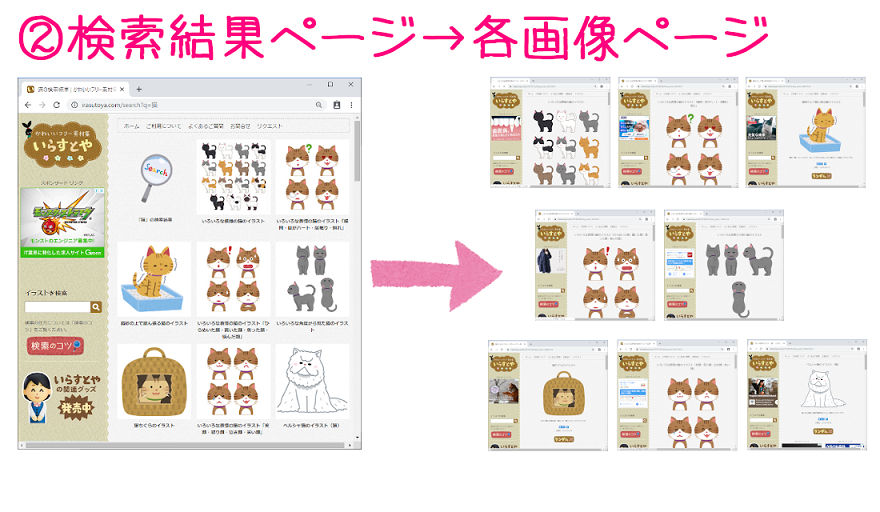
検索結果ページのhtmlを文字列にしてから、タグや属性を使って、画像ページのURLが書かれている箇所をひとつひとつ特定していきます。
検索結果ページのURLからhtmlを取得
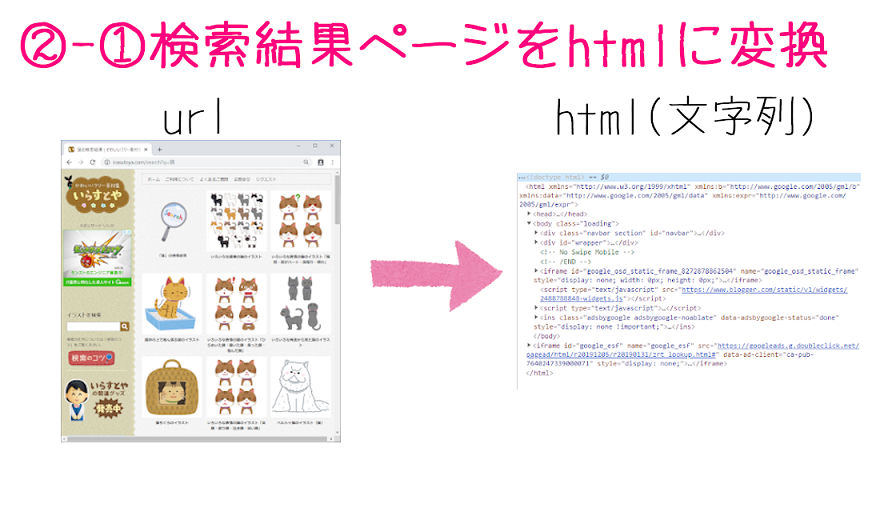
17行目:
html = requests.get(url).text
requests.get(url)で、検索結果ページ(変数url)からデータ(Responseオブジェクト)を取得します。
そして、オブジェクトのtext属性を使って、htmlの文字列で取り出します。
そして取得した検索結果ページのhtmlを、変数htmlとします。
検索結果ページのhtmlからBeautifulSoupオブジェクト取得
19行目:
soup = BeautifulSoup(html, 'lxml')
BeautifulSoup(html, 'lxml')で、検索結果ページのhtml(変数html)からBeautifulSoupオブジェクトを作成して、変数soupとします。
BeautifulSoupオブジェクトにすると、タグや属性を使って、ページから欲しい要素を探すことができるようになります。
画像リンクのあるaタグをすべて取得
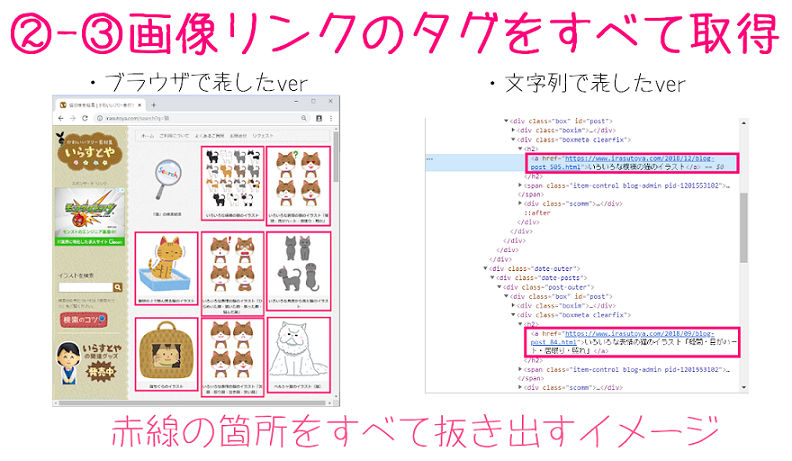
21行目:
a_list =soup.select('div.boxmeta.clearfix > h2 > a')
soup.select('div.boxmeta.clearfix > h2 > a')で、BeautifuSoupオブジェクト(変数soup)から、指定したタグの要素(tagオブジェクト)を全て抽出します。
今回は画像リンクを含んでいるaタグ'div.boxmeta.clearfix > h2 > a'を抽出します。
そして取得したaタグのリストを、変数a_listとします。
欲しい要素のセレクターや属性、XPathなどを簡単に取得する方法
スクレイピングやseleniumを使うために、要素のセレクターを下のように取得したい。
div.boxmeta.clearfix > h2 > a
どうやって取得するか?パッと簡単にできる方法を解説します。
Googleクロームなどで欲しい要素にカーソルを合わせてそのまま右クリック→検証を押します。
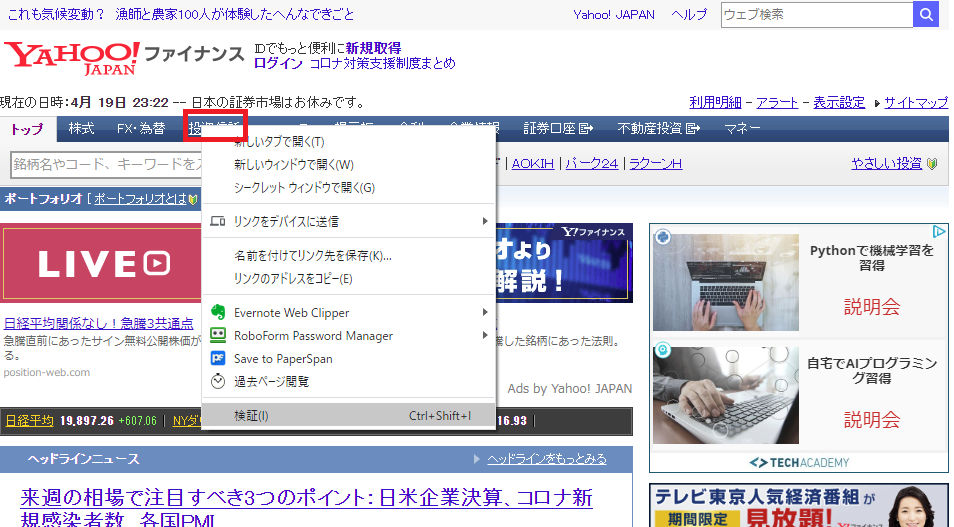
すると、ディベロッパーツールがカーソルを合わせた部分をすでに選択した形で開いてくれているので、ここで右クリック→Copyをすると色々コピーできます。
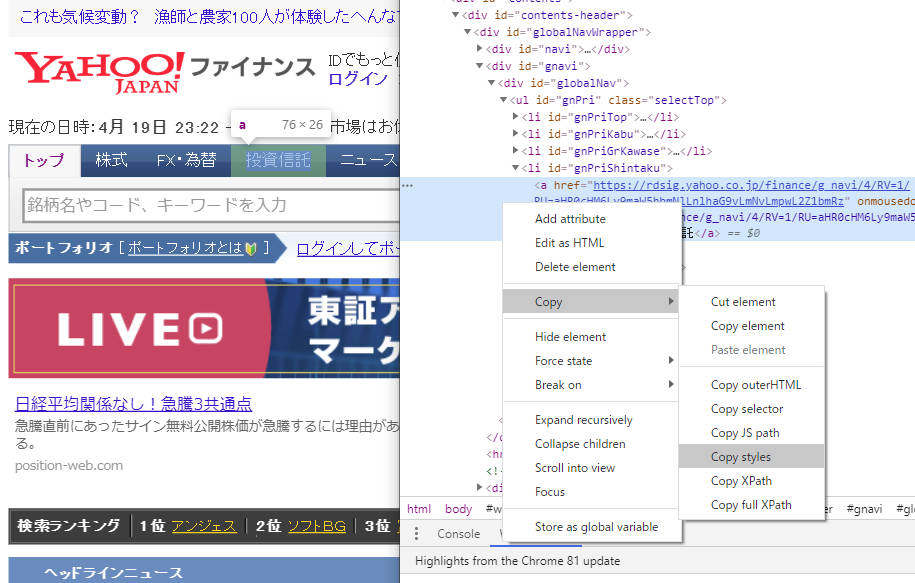
後は自分の使いたいものをコピーして使って下さい。
aタグを1つずつ取り出してfor文の処理
次は取得したaタグをリストにしたa_listの中から一つずつ取り出してfor文以下の処理をしていきます。
23行目:
for a in a_list:
図で表すと以下のようになります。
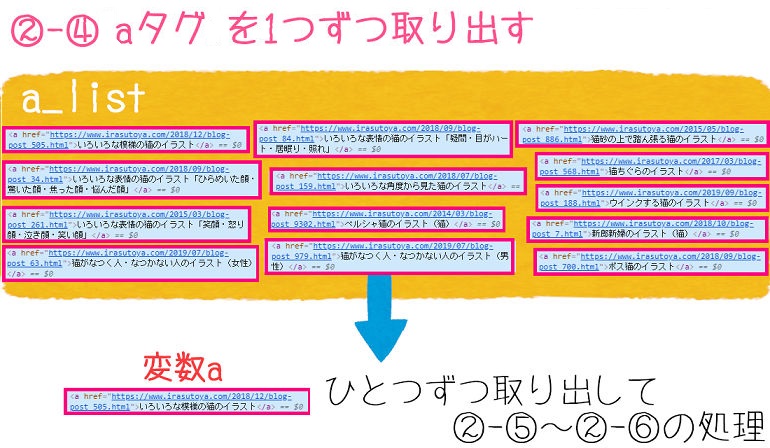
取り出したaタグの要素を変数aとして、②-⑤から②-⑥を1つずつループ処理します。
aタグからURLを抽出
次はaタグからurlだけを取り出します。
25行目:
link_url = a.attrs['href']
a.attrs['href']で、aタグのtagオブジェクト(変数a)から画像ページのURL(href属性)を取り出せます。
そして取り出した画像ページのURLを、変数link_urlとします。
URLをリストに追加
27行目:
linklist.append(link_url)
linklist.append(link_url)で、画像ページのURL(変数link_url)を、画像ページの一覧リスト(変数linklist)に追加します。
すべてのURLを追加できたら、③ブロックでURLにひとつずつアクセスして、画像ファイル本体のURLを探していきます。
各画像ページにある画像ファイルのURLを特定
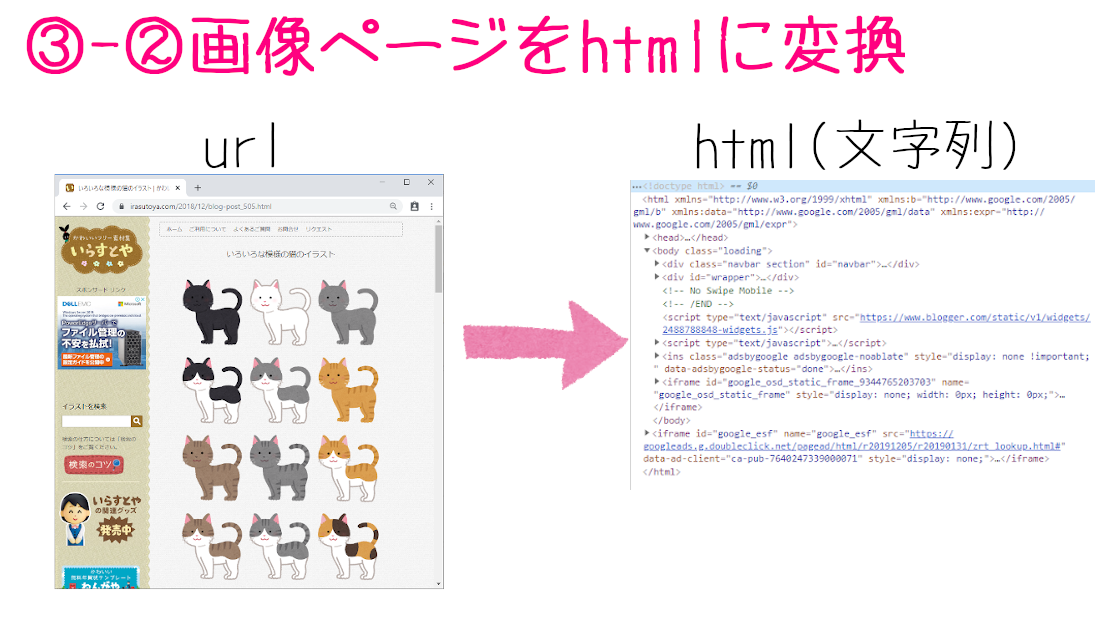
3つ目のブロックは、それぞれの画像ページにある画像ファイルを特定する処理です。
検索結果ページと同じように、それぞれの画像ページをhtmlの文字列に変換してから、タグや属性を手掛かりにして、画像ファイル自体のURLを調べていきます。
画像ページのURLを1つずつ取り出す
30行目:
for page_url in linklist:
for文で、リスト(linklist)から画像ページのURLを1つずつ取り出します。
そして取り出したURLを変換page_urlとして、③-②から④-④までの処理を、リストにある全てのURLにループ処理していきます。
画像ページのhtmlを取得
33行目:
page_html = requests.get(page_url).text
requests.get(page_url)で、画像ページ(変数page_url)からResponseオブジェクトを取得します。
そしてオブジェクトのtext属性を使い、htmlの文字列を取り出して、変数page_htmlとします。
画像ページのBeautifulSoupオブジェクトを作成
35行目:
page_soup = BeautifulSoup(page_html, "lxml")
BeautifulSoup(page_html, "lxml")で、画像ページのhtml(変数page_html)からBeautifulSoupオブジェクトを作成します。
こうすることで、タグや属性を使って要素を探すことができる状態になりました。
作成した画像ページのBeautifulSoupオブジェクトは、変数page_soupとします。
画像ファイルのあるタグをすべて抽出
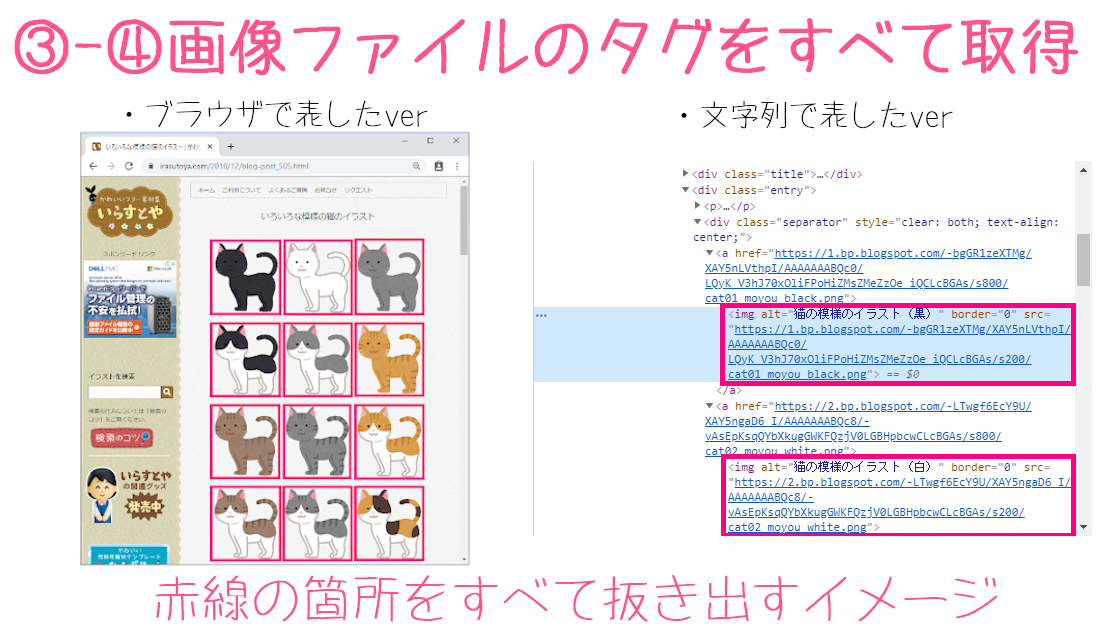
37行目:
img_list = page_soup.select('div.entry > div > a > img')
page_soup.select('div.entry > div > a > img')で、BeautifuSoupオブジェクト(変数page_soup)から、指定したタグ
の要素(tagオブジェクト)をリストで全て抽出します。
ここでは画像ファイルを含まれているimgタグ'div.entry > div > a > img'を抽出して、取得したリストを変数img_listとします。
画像ファイルのタグを1つずつ取り出す
39行目:
for img in img_list:
for文で、画像ファイルのリスト(変数img_list)から、imgタグの要素(tagオブジェクト)を1つずつ取り出します。
そして取り出したimgタグの要素を変数imgとして、③-⑥~④-④をループ処理していきます。
画像ファイルのURLを抽出
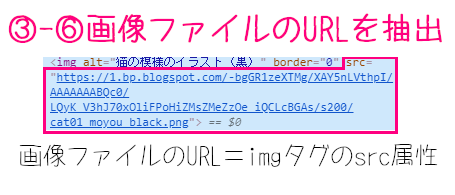
41行目:
img_url = (img.attrs['src'])
(img.attrs['src'])で、imgタグの要素(変数img)から画像ファイルのURL(src属性)の文字列を抽出します。
そして取り出した文字列を、変数img_urlとします。
これが画像ページではなく、その中にある画像ファイル自体のURLになります。
画像ファイルの名前を抽出
43行目:
filename = re.search(".*\/(.*png|.*jpg)$",img_url)
re.search(".*\/(.*png|.*jpg)$",img_url)で、画像ファイルのURL(変数img_url)から、ファイル名を取り出します。
第一引数の(".*\/(.*png|.*jpg)$",img_url)では、正規表現で画像ファイルを指定しています。
出てくる正規表現を解説しておくと、下記のようになります。
.=任意の1文字*=直前の正規表現の0回以上の繰り返し\=特殊文字をエスケープ|=前か後いずれかの正規表現にマッチ$=文字列の末尾の改行の直前この返り値はmatchオブジェクトなので、いったん変数filenameとして、次の行で文字列に変換します。
保存先のファイルパスを作成
45行目:
save_path = output_folder.joinpath(filename.group(1))
output_folder.joinpath(filename.group(1))で、画像ファイルを出力フォルダに保存するためのファイルパスの文字列を作ります。
filename.group(1)は、matchオブジェクト(変数filename)で条件にマッチした文字列で、画像ファイルのファイル名です。
ですので、「いらすとや/〇〇.png」または「いらすとや/〇〇.jpg」というファイルパスになります。
このファイルパスを変数save_pathとして、ここから実際に保存していきます。
画像ファイルのURLからデータをダウンロード
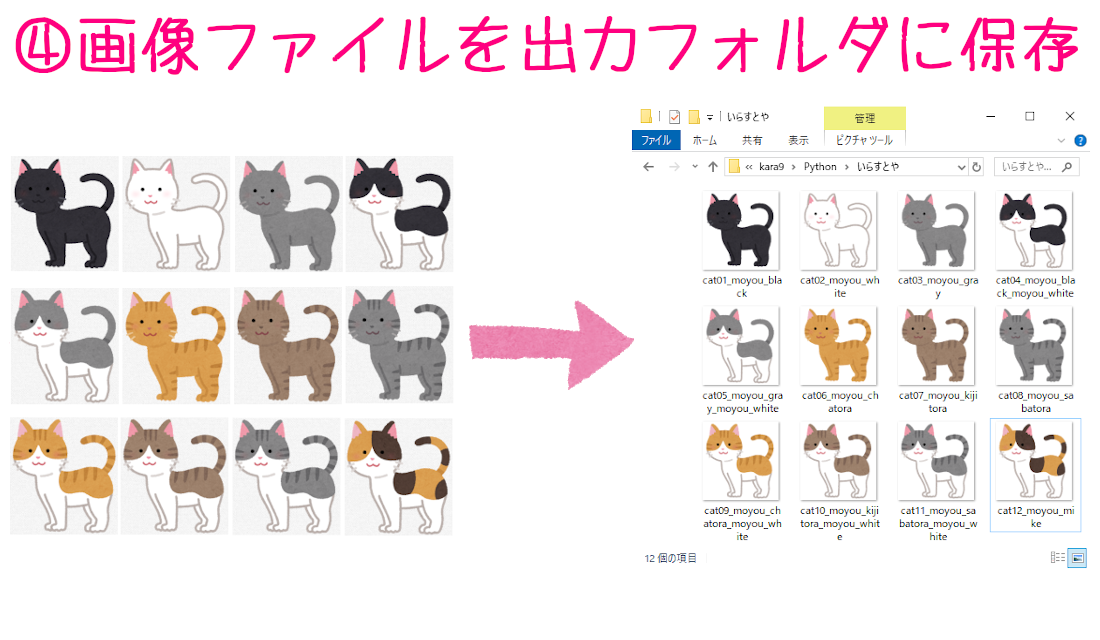
最後のブロックでは、ここまで集めた情報を使って、画像ファイルを出力フォルダに保存していきます。
この部分はtry-except文にして、エラーが起きてもプログラムが止まらないようにしています。
tryの処理を行っていき、エラーが起きた場合だけexceptの処理に移ります。
ソースコードをもう一度確認する
画像ファイルのデータを取得
50行目:
image = requests.get(img_url)
requests.get(img_url)で、画像ファイルのURL(変数img_url)から画像ファイルのResponseオブジェクトを取得します。
取得した画像ファイルのオブジェクトは、変数imageとします。
出力フォルダにデータを保存
52行目:
open(save_path, 'wb').write(image.content)
open(save_path, 'wb')で出力先のファイルパス(変数save_path)を書き込みモード(wb)で開いてから、write(image.content)で画像ファイル(変数image)のバイナリデータ(content属性)を書き込んで保存します。
ここでようやく画像をダウンロードすることができました。
保存したファイル名を表示

53行目:
print(save_path)
print(save_path)で、保存した画像のファイルパス(変数save_path)を表示します。
プログラムを実行すると、スクレイピングが成功した画像ファイルだけどんどん表示されていき、失敗した場合は次のエラーが表示されます。
失敗した場合はエラー表示
57行目:
print("ValueError!")
「ValueError!」というエラーメッセージを表示します。
こちらのexcept文は、④-①から④-③でエラーが起きた場合のみ実行される処理です。
③-⑥で取り出したURLが画像ファイルでなかった場合などに起こります。
プログラムを実行していただいたり、改良して@uury112をつけてメンション付きのツイートをしていただければ(https://twitter.com/uuyr112)でリツイートさせていただきます。


コメント