
機械学習とは何か?について以前解説しましたが、その機械学習にとってジレンマともいえるのが、『過学習』という問題です。
「学習したデータは正確に予測できるけど、未知の知らないデータに対しては正解を出すことができない」現象です。
この過学習の状態になると実際の運用には全く使えなくなるので注意しないといけません。
ここでは、過学習の具体的な例とその過学習を解消するいくつかの方法について解説していきます。
そもそも機械学習について知りたい方は、以前に解説したこちらの記事も読んでみて下さい↓

学習すべきことを学習できていない『過学習』
『過学習』は英語で「overfitting」(過剰適合)ともいいます。
その名の通り、過学習=過剰に学習データに適合しすぎた状態と覚えておいてください。

実際に過学習の例を紹介します。
気温とアイスの売り上げの相関関係を回帰予測する機械学習モデルです。
①下の図は学習データとテストデータも反映した一般的なモデルです。
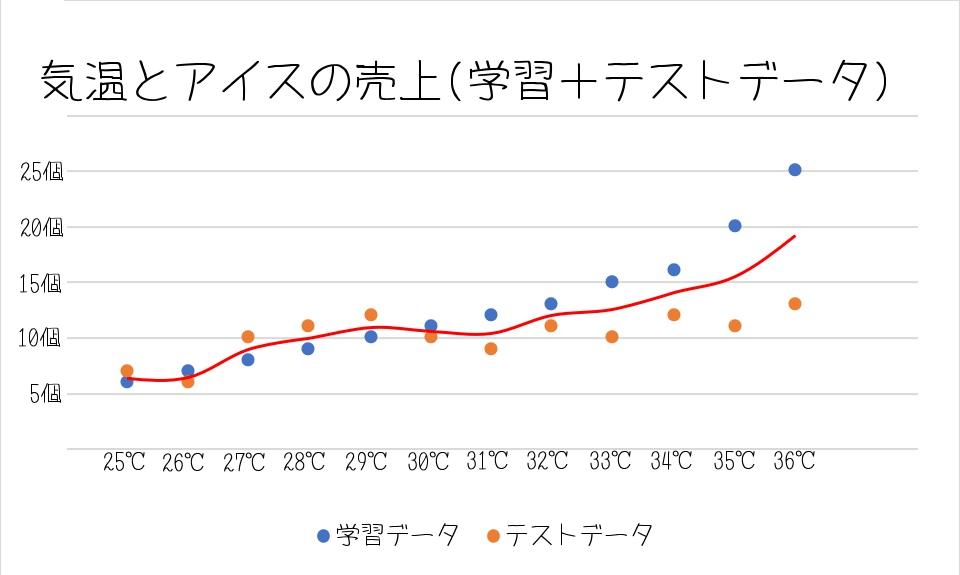
画像にある赤線が、AIが学習データから学んだ法則「モデル」になります。
こちらは、学習データに依存しすぎず、ちゃんと予測ができています。
②下の図は学習データだけを反映した『過学習』モデルです。
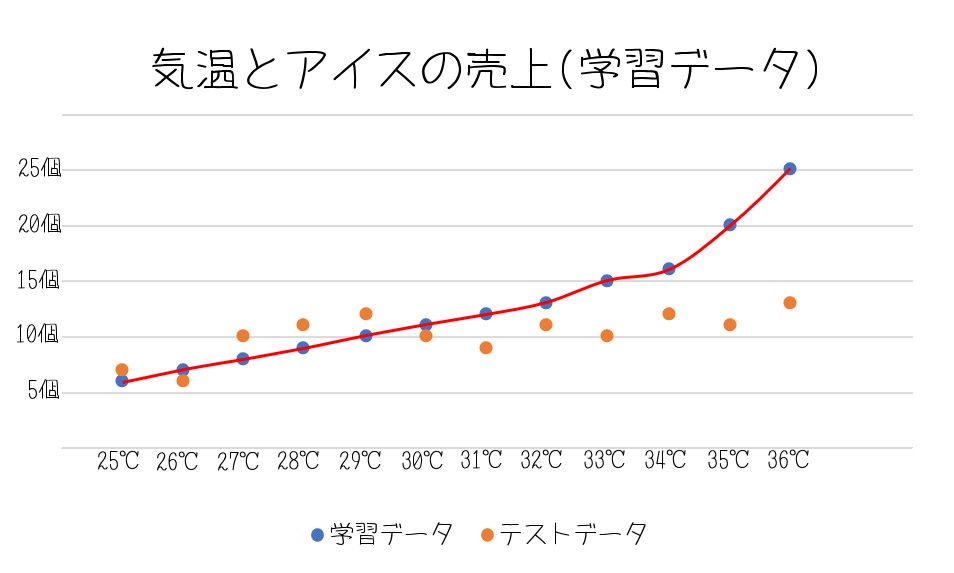
モデルが学習データに寄りすぎて、未知のデータとは外れてしまっていますね。
学習データだけには正確ですが、それ以外のデータでは役に立ちません。
学習データについて学習しすぎた実際には役に立たない過学習モデルとなってしまっています。
過学習の原因は間違ったパターンの学習
学習データを重視しすぎることで、どのような不具合が起こるのでしょうか。
過学習の直接的な原因は「学習しなくていい特徴を学習してしまうこと」にあります。
例えば「動物の画像に対して、その種類を判別する」という機械学習をさせるとします。
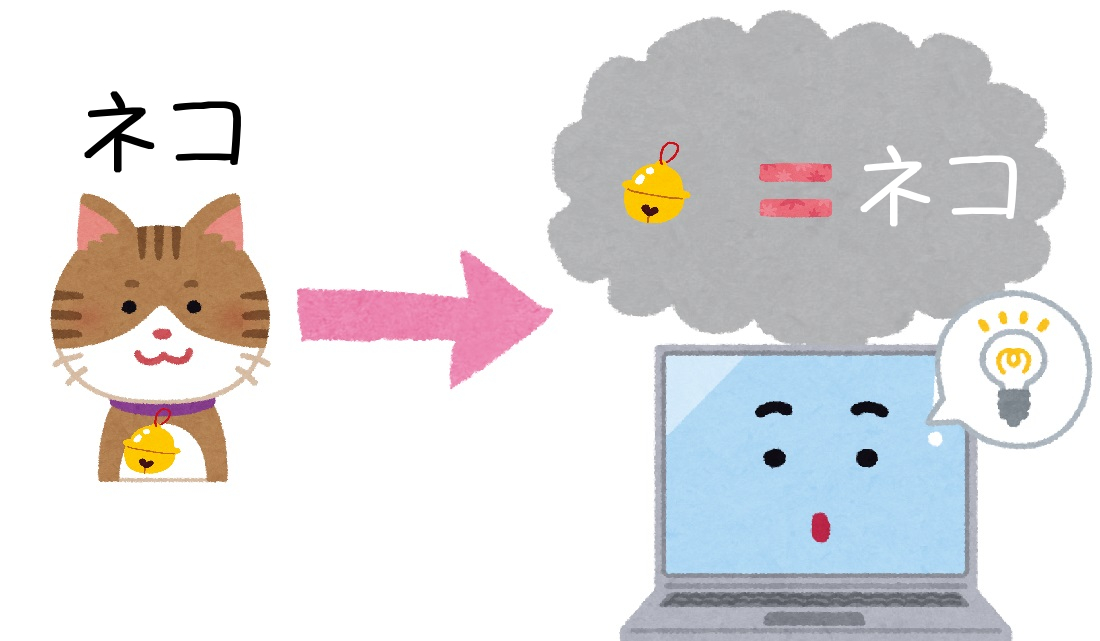
もし学習データでネコが鈴をつけていた場合、「鈴をつけている動物=ネコ」という間違ったパターンを学習をしてしまうことがあります。
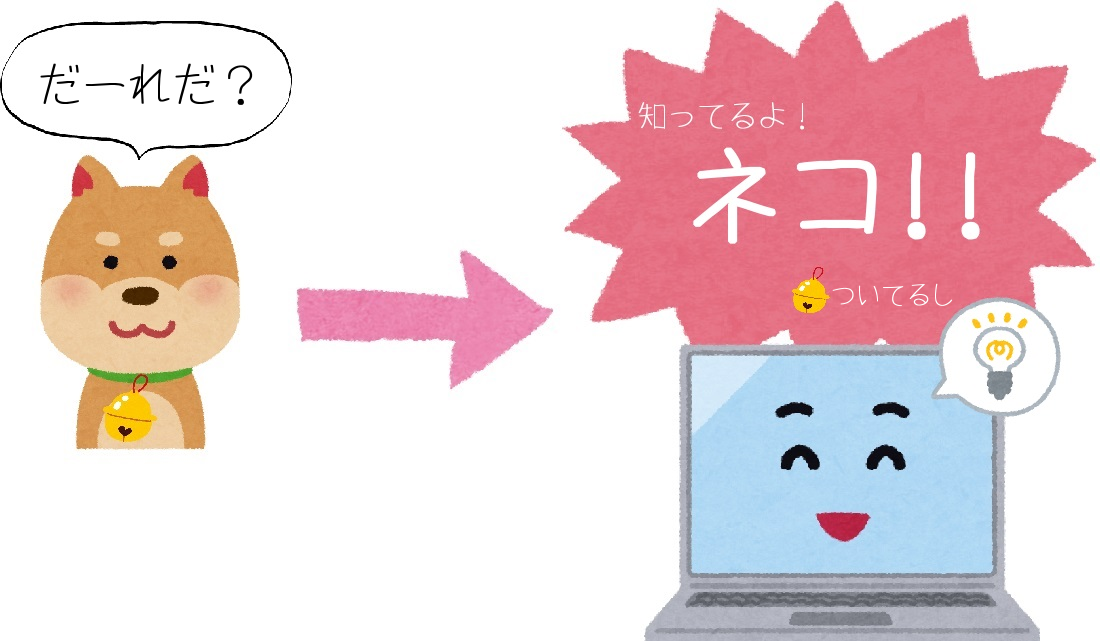
すると、鈴をつけている犬の画像が出てきても、ネコだと判断してしまうのです。
このように間違ったモデルを学習してしまった状態が『過学習』です。
『過学習』を防ぐ方法は、学ぶべきデータだけ学習させること
機械学習の『過学習』を防ぐには、いくつかの方法があります。
共通しているのが、学ばなくていいデータを学ばせずに、学ぶべきデータを学ばせることです。
パターンを見つけるため『学習データを増やす』
まず1番は『学習データの量を増やす』ことです。
学習データの量が少ないと、AIがデータの傾向を学習できていないことがあります。
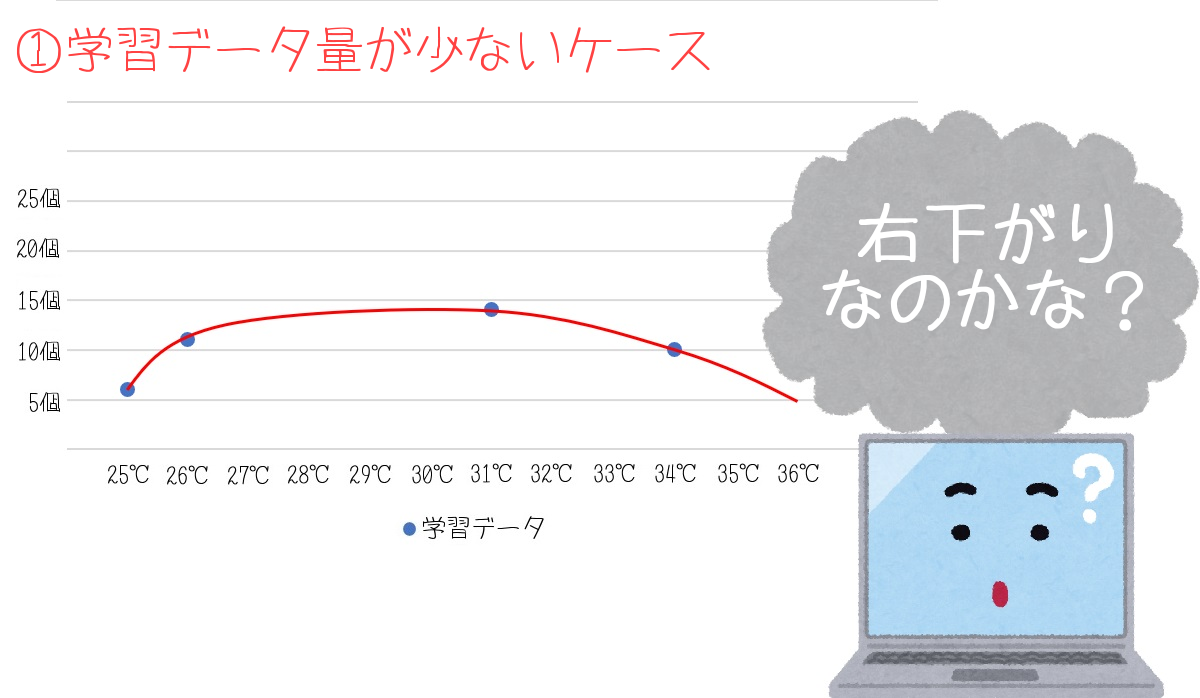
①の画像は、4個のデータをまとめたグラフです。
この4個のデータだけを見ると、右肩下がりのグラフだと学習できますね。
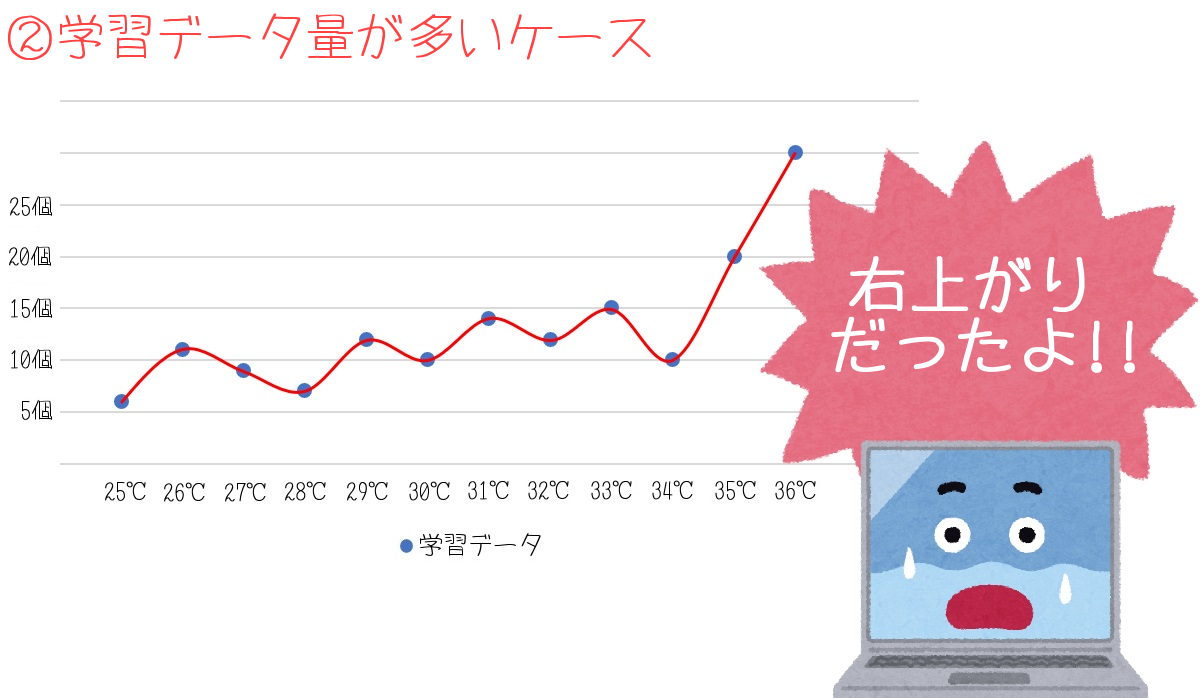
②の画像は、①に8個のデータを加えた、12個のデータのグラフです。
データを増やしたところ、実は右肩上がりのグラフだったことがわかりました。
①の状態では、学ぶべきデータを学習できていなかったことになります。
より多くのデータを学ばせることで、学ぶべきデータを学習させようという方法です。
極端なデータは無視させる『正則化』
つづいては『正則化』という方法です。
簡単にいうと、「学習しなくていいデータを無視すること」です。
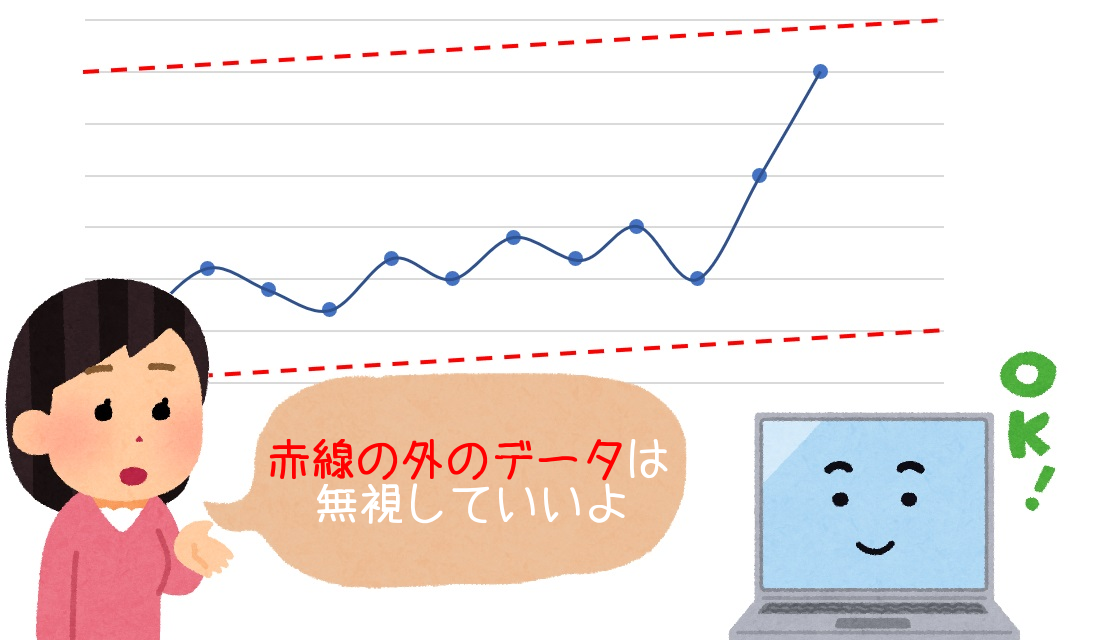
『過学習』の状態だと、例外のような極端なデータも学習して、モデルに反映してしまいます。
すると、極端なデータに適合した結果、一般的なデータに対応できなくなってしまうのです。
『正則化』では、学習しなくていい極端なデータを無視するように調整します。
モデルの形が複雑になりすぎないように、ギプスみたいに矯正してあげるイメージです。
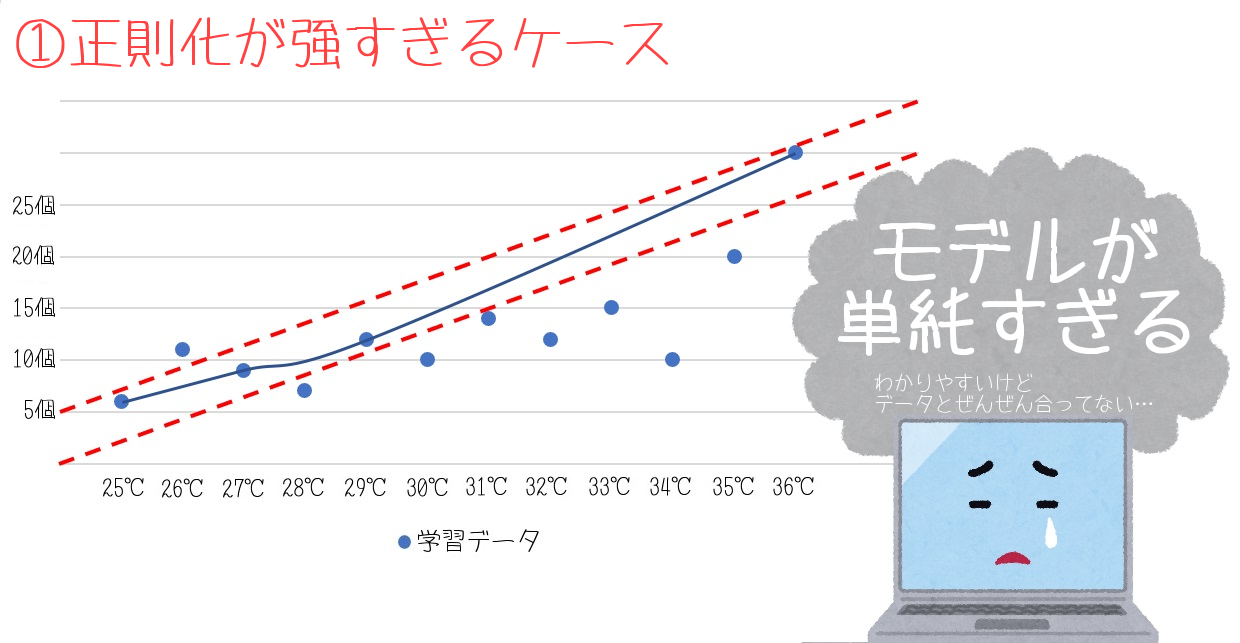
①のグラフは、正則化が強すぎるケースです。
極端なデータを無視することで、直線のようなモデルになりました。
明確に右肩上がりとわかるモデルですが、わずかな例外も許さないので、汎用性が低いです。
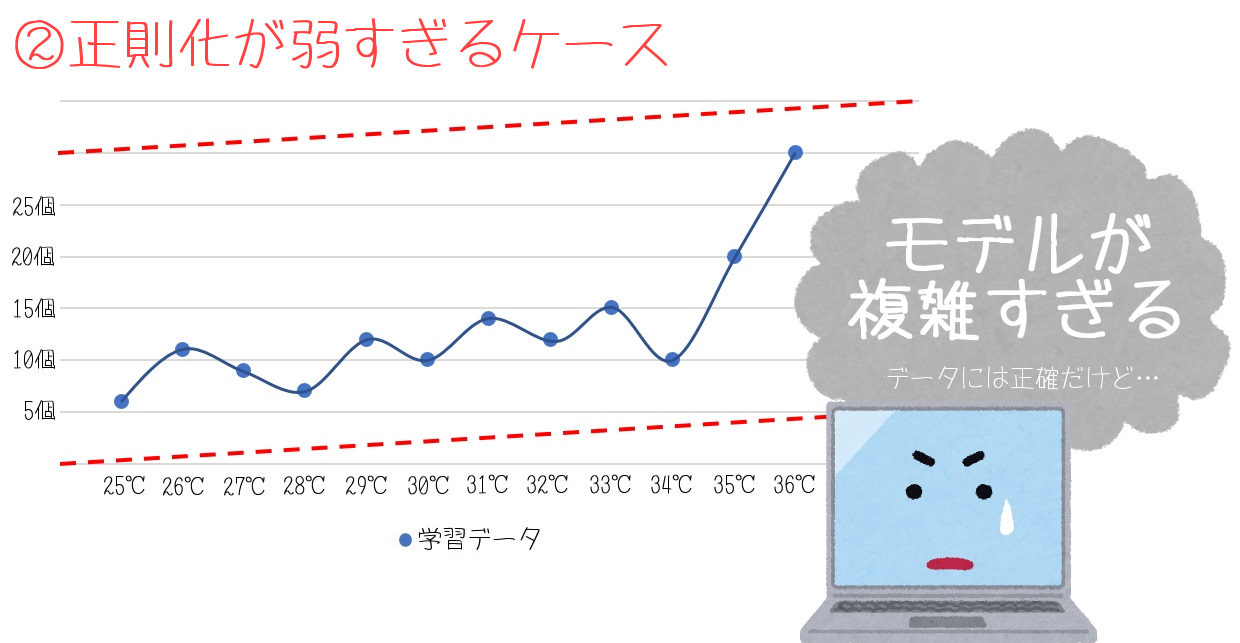
②のグラフは、正則化が弱すぎるケースです。
極端なデータにも適合した結果、ぐにゃぐにゃで法則の分からないモデルになりました。
絵に描いたような『過学習』のモデルになっていますね。
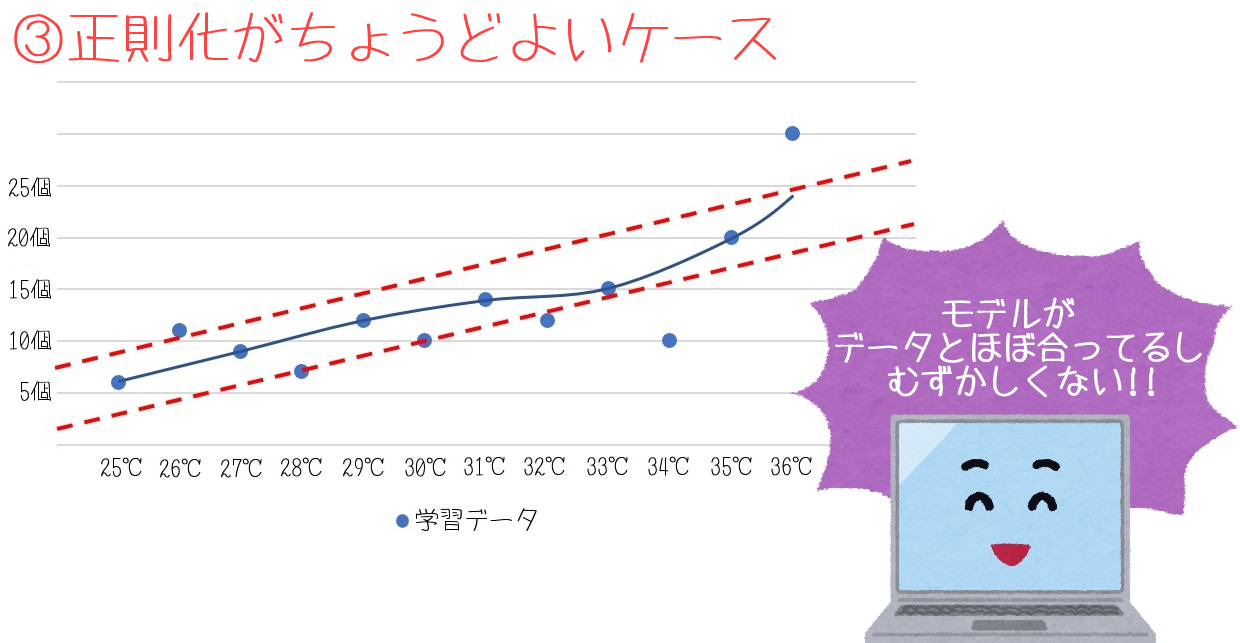
③のグラフは、正則化が丁度よいケースです。
極端すぎるデータだけを無視することで、ある程度の汎用性はもったモデルになりました。
右肩上がりという法則は汲みつつ、多少の例外にも対応できる幅を持っていますね。
偏ったデータをシャッフルする『交差検証』
3つ目は『交差検証』です。
これは偏った学習にならないように、「学習データをシャッフルする」ことです。
機械学習では、学習データで学習して、テストデータで検証を行います。
しかし1回の学習では、学習するべきデータを学習できていないかもしれません。
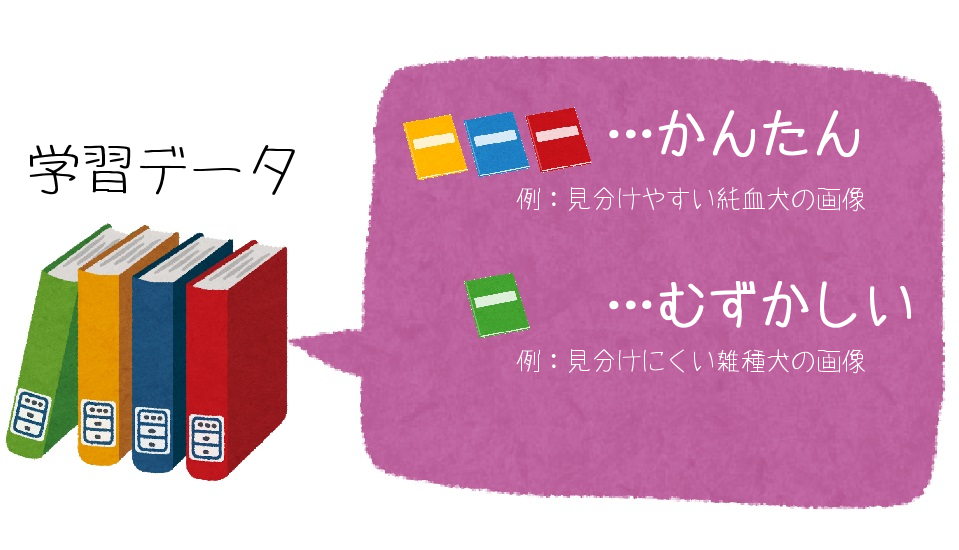
例えば、与えられたデータの中でも、簡単なデータと難しいデータがあったとします。
機械学習では、これを学習データとテストデータに分けて、学習と検証を行います。
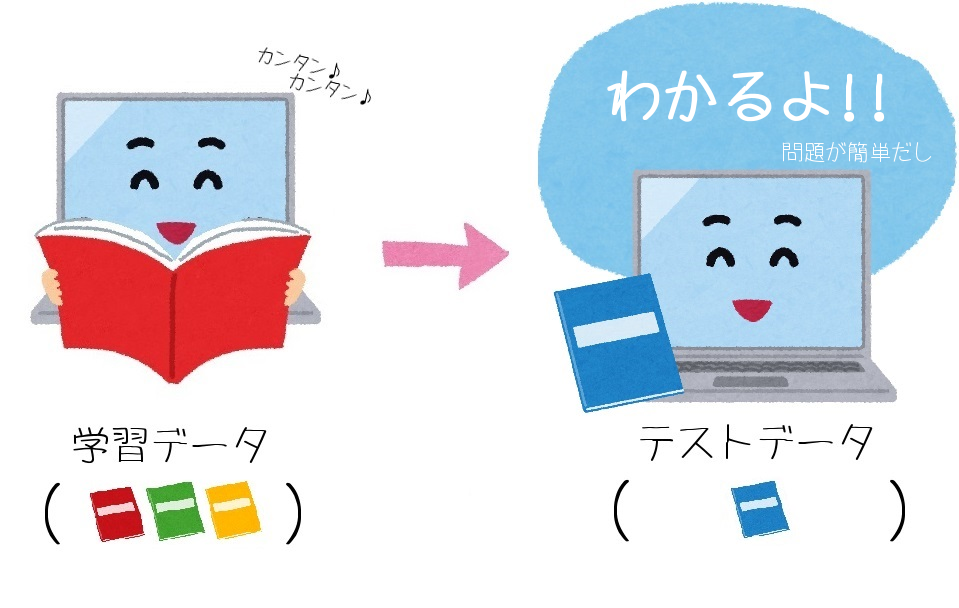
①学習データに難しいデータがあった場合
難しいデータを学習しているので、AIは検証のテストデータも解くことができますね。
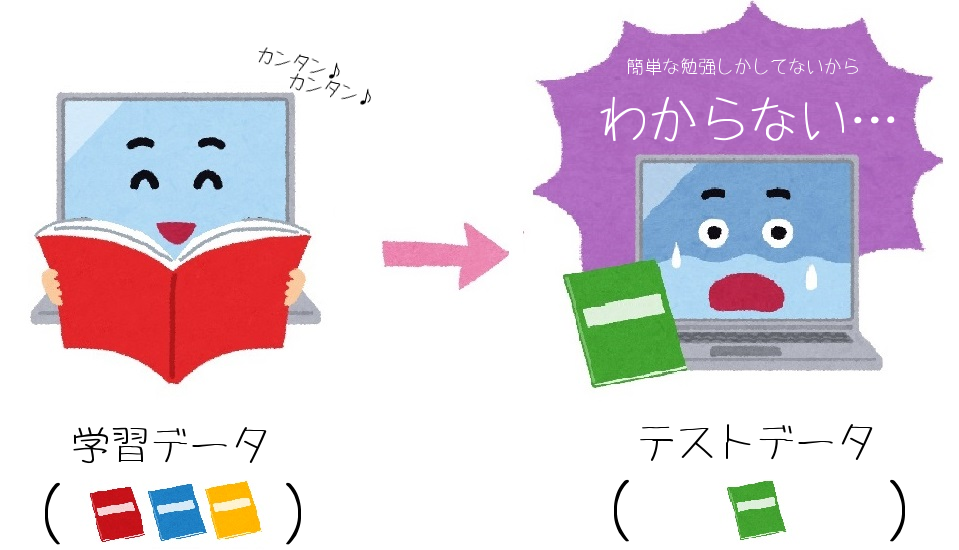
②学習データに簡単なデータしかなかった場合
簡単なデータしか学習していないので、AIは難しいテストデータを解くことはできません。
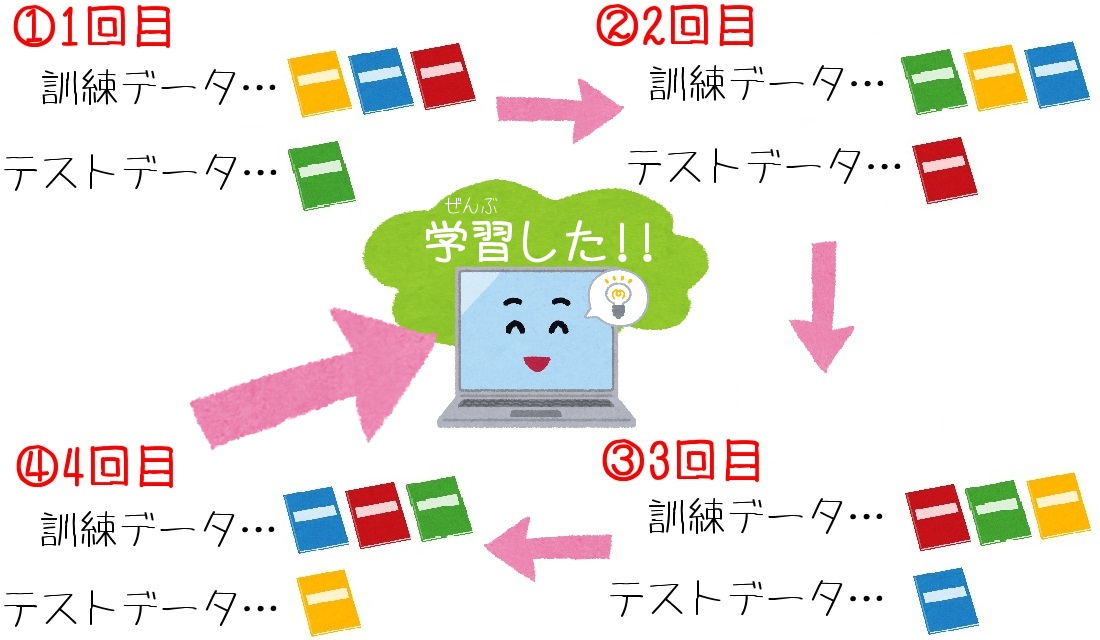
そこでデータを何回もシャッフルして検証することで、偏った学習を防ぐことができます。
さまざまなデータに触れる機会を作って、難しいデータを学習できるようにするのです。
まとめ
ここまでが過学習の解消法です。
過学習という現象は機械学習をやっていると頻繁ではないですが、遭遇すると思います。
データの扱い方を変えるだけで結果が大きく違ってくるので、気を付けていきたいところです。
コメント