
今回のPythonのプログラムは複数の画像にテキストを一気に入れて、アイキャッチ画像を作るプログラムです。
実は、このブログのアイキャッチも全部プログラムで一気に作っています。
例えばこんな感じでできるよ↓

このプログラムを使えば、画像ソフトを使わなくてもテキストを入れたアイキャッチを何枚でも一括で次のように作ることができます↓

このプログラムの文字フォントや位置、大きさなどをカスタマイズすることで、instagramに投稿する画像なども時間をかけずに簡単に作ることが可能です。
今回はPythonで画像に文字入れして、綺麗なアイキャッチを作るプログラムだよ
Pythonだけでとても綺麗な画像が作れるんだね
ちょっと応用すれば、大量にあるinstagramの画像に一括で文字入れすることも簡単にできるよ
プログラムのソースコード
ファイル名:prog.py
import csv
import matplotlib.pyplot as plt
import numpy as np
import os
from PIL import Image, ImageDraw, ImageFont
SETTING_CSV = "setting.csv"
INPUT_DATA_DIR = "./input"
OUTPUT_DATA_DIR = "./output"
IMG_Q = 90
IMG_SIZE = (780, 428)
TEXT_SIXE = (750, 200)
TEXT_MARGIN = 30
MAX_FONT_SIZE = 100
FONT_PATH = "./fonts/migmix-1p-bold.ttf"
TEXT_COLORS = (('black', '#000000', (255, 255, 255, 192)),
('white', '#FFFFFF', (0, 0, 0, 192)))
def make_eye_catch(img_path, text):
# 画像のファイル名を取得
file_name, ext = os.path.splitext(img_path)
# \n(改行指定)でテキストを分割
text = text.split(r"\n")
# 先に文字の描画領域決定。合わせて下記を計算しておく
# フォントサイズfont_size, 描画幅area_width, 描画高さarea_height, lines_size
for font_size in range(MAX_FONT_SIZE, 9, -1):
# フォント
font = ImageFont.truetype(FONT_PATH, font_size)
# 各行の[幅、高さ]を計算
lines_size = [list(font.getsize(t)) for t in text]
# 幅の最大と高さの合計
area_x = np.max(lines_size, 0)[0]
area_y = np.sum(lines_size, 0)[1]
if(area_x <= TEXT_SIXE[0] and area_y <= TEXT_SIXE[1]):
break
# 画像読み込み、サイズ取得
img = Image.open(os.path.join(INPUT_DATA_DIR, img_path))
original_img_size = img.size
# 縮小
if (original_img_size[0] / original_img_size[1]) \
>= (IMG_SIZE[0] / IMG_SIZE[1]):
# 目標より横長なら、縦横比を維持して、縦を目標まで縮める
img.thumbnail((original_img_size[0], IMG_SIZE[1]))
thumbnail_size = img.size
# 横幅を切り取るための計算をする
crop_left = int((thumbnail_size[0] - IMG_SIZE[0]) / 2)
crop_upper = 0
crop_right = crop_left + IMG_SIZE[0]
crop_lower = IMG_SIZE[1]
else:
# 目標より縦長なら、縦横比を維持して、横を目標まで縮める
img.thumbnail((IMG_SIZE[0], original_img_size[1]))
thumbnail_size = img.size
# 縦幅を切り取るための計算をする
crop_left = 0
crop_upper = int((thumbnail_size[1] - IMG_SIZE[1]) / 2)
crop_right = IMG_SIZE[0]
crop_lower = crop_upper + IMG_SIZE[1]
# 計算した縦横で切り取る
img = img.crop((crop_left, crop_upper, crop_right, crop_lower))
# 背景の塗りつぶしと文字書き込み準備
rectangle_y = area_y + TEXT_MARGIN
rectangle_top = int((IMG_SIZE[1]-rectangle_y)/2)
# 白黒2色分画像を作成
for (label, fg_color, bg_color) in TEXT_COLORS:
# 塗りつぶし領域作成
rectangle_img = Image.new('RGBA', img.size)
draw = ImageDraw.Draw(rectangle_img)
draw.rectangle((0, rectangle_top, IMG_SIZE[0],
rectangle_top+rectangle_y), bg_color)
# 塗りつぶし
org_img = img.convert('RGBA')
new_img = Image.alpha_composite(org_img, rectangle_img)
draw = ImageDraw.Draw(new_img)
_y = int((IMG_SIZE[1]-area_y)/2)
for (t, line) in zip(text, lines_size):
_x = int((IMG_SIZE[0]-line[0])/2)
draw.text((_x, _y), t, font=font, fill=fg_color)
_y += line[1]
new_img = new_img.convert("RGB")
res_file_name = file_name + "_" + label + ".jpg"
new_img.save(os.path.join(OUTPUT_DATA_DIR, res_file_name),
quality=IMG_Q)
plt.figure()
plt.imshow(new_img)
def main():
input_data_list = []
with open(SETTING_CSV, "r", encoding="shift-jis") as csv_file:
reader = csv.DictReader(csv_file)
for row in reader:
input_data_list.append([row["path"], row["sentence"]])
# outputフォルダが存在しなければ作る
if not os.path.exists(OUTPUT_DATA_DIR):
os.makedirs(OUTPUT_DATA_DIR)
# アイキャッチ画像の生成
for img_path, text in input_data_list:
make_eye_catch(img_path, text)
info_msg = "[INFO] {0}の処理が完了しました"
print(info_msg.format(os.path.join(INPUT_DATA_DIR, img_path)))
print("[INFO] Finish!!")
if __name__ == "__main__":
main()
【プログラム実行前の準備】
一見すると難しそうな今回のプログラムですが、必要な準備はたったの3つだけです。
まずはじめに、アイキャッチの背景の画像ファイル、CSVファイルの準備をしておきましょう。
【最新】はじめてPythonをインストールするための手順についてOS別(Windows10, Mac)で解説
アイキャッチを入れたい画像を「input」フォルダへ
今回のプログラムは「input」という名前のフォルダ内にある画像に対して、アイキャッチを挿入してくれます。ですので、プログラムを実行する前に「input」というフォルダを作成し、その中へ画像を準備しておきます。

アイキャッチを入れた画像は「output」という名前のフォルダに出力されます。
もし「output」フォルダが無い場合、プログラムが自動で作成してくれるので、準備する必要はありません。
CSVファイルで作成したい画像と文字を設定する
settinng.csvというcsvファイルを作成して、作成したいアイキャッチの文字列とタイトルを入れておきます。Excelでsetting.csvを開き、画像とテキストに関する情報を入力しておきましょう。
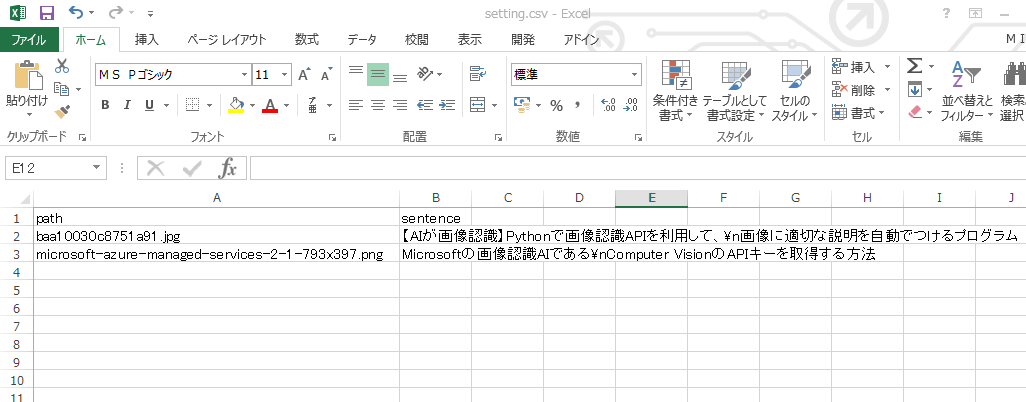
セルA2のpathの列には、アイキャッチの元にしたい画像のファイル名を入力します。
セルB2のsentenceの列には、アイキャッチに挿入したいテキストを入力します。
テキストで改行を入れたい部分には、改行コード(\n)を入れます。
例えば、
明日の天気は
晴れです
このように改行のあるフレーズに仕上げたい場合、
「明日の天気は\n晴れです」
と入力してください。
3つの外部ライブラリをインストールします
prog.pyでは、Pythonに本来入っていない拡張機能を使うため、外部ライブラリのインストールが必要です。エラーの原因になるので、インストールはプログラムprog.pyの実行前に行いましょう。
Macの場合はターミナル、Windowsの場合はコマンドプロンプトで
プログラムpost.pyが置いてあるディレクトリーに移動して、
pip install pillow
pip install matplotlib
pip install numpy
と入力するだけで、インストールできます。
(もしすぐに使ってみたい方は、ひとまずここまでの準備で、コマンドプロンプトまたはターミナルで、カレントディレクトリに移動して、python prog.pyと打つことで、プログラムを実行可能です。)
ソースコードの詳細な解説
ではここからソースコードの詳細な解説に移りたいと思います。
prog.pyで使うライブラリをインポート
1から5行目では、プログラムを動かすために必要なライブラリをimportしています。
import csv import matplotlib.pyplot as plt import numpy as np import os from PIL import Image, ImageDraw, ImageFont
それぞれのライブラリについて軽く解説していきます。
matplotlib・osについては、以前の解説を参考にしてください。
Pythonのモジュールの使い方。パッケージやライブラリとの違いも解説
csvモジュール
CSVファイルを読み込み・書き出しするために、必要なモジュールです。
numpyライブラリ
数値計算を効率よく行うライブラリです。
ベクトルや行列など、難しい演算が必要なデータも効率よく処理することができます。
アイキャッチ画像に関するパラメータの設定
8行目から18行目の変数へ値を代入している部分では、アイキャッチ画像に関するパラメータを設定しています。
SETTING_CSV = "setting.csv"
入力画像のパスとテキストの設定が記載されたCSVファイルを指定します。
INPUT_DATA_DIR = "./input"
テキストを挿入したい画像を読み込む、入力データのフォルダパスの変数をINPUT_DATA_DIRとします。
OUTPUT_DATA_DIR = "./output"
テキストを挿入した画像を書き出す、出力データのフォルダパスを変数をOUTPUT_DATA_DIRとします。
IMG_Q = 90
入力ファイルに対する出力ファイルのイメージクオリティ(%)を表す変数をIMG_Qとします。
IMG_SIZE = (780, 428)
出力するアイキャッチ画像のサイズの変数をIMG_SIZEとします。
TEXT_SIXE = (750, 200)
画像に挿入するテキストのサイズの変数をTEXT_SIXEとします。
TEXT_MARGIN = 30
画像に挿入するテキストのマージン(空白間隔)サイズの変数をTEXT_MARGIN とします。
MAX_FONT_SIZE = 100
画像に挿入するテキストのフォントのサイズの変数をMAX_FONT_SIZEとします。
FONT_PATH = "./fonts/migmix-1p-bold.ttf"
画像に挿入するテキストで使うフォントのパスの変数をFONT_PATHとします。
今回は予めfontsフォルダにmigmixフォントを用意しておきました。
TEXT_COLORS = (('black', '#000000', (255, 255, 255, 192)),
('white', '#FFFFFF', (0, 0, 0, 192)))
挿入するテキストのカラーを指定する変数をTEXT_COLORSとしています。
()の中身はそれぞれ、(色の名称,前景色,背景色)を指しています。
make_eye_catch関数の定義
21行目から91行目は長いですが、画像に背景付きテキストを入れてアイキャッチを作るmake_eye_catch関数をdef文によって定義しています。
def make_eye_catch(img_path, text):
ここから以下の処理が、アイキャッチ画像を作成する部分になります。
23行目
file_name, ext = os.path.splitext(img_path)
ここでは、ファイルのパスと拡張子を取得しています。
os.path.splitext(ファイルのパス)
でファイルのパスと拡張子をそれぞれ分離して取得できます。
例えば、
filepath = "/root/net/web.html"
print(os.path.splittext(filepath) = {"/root/net/web", ".html"}
となります。今回の場合filenameにファイルの名前、extに拡張子がそれぞれ代入されます。
text = text.split(r"\n")
\n(改行指定)で、テキストを分割するように設定しています。
変数for font_sizeを使ったループ処理
29行目
for font_size in range(MAX_FONT_SIZE, 9, -1):
for文を使った繰り返しの処理です。
ここで、range関数が出てきました。
一般的にrange(a, b, 1)
でaからb-1まで昇順で間隔が1刻みでリストを返します。
range(a, b, -1)とあった時、第3引数の-1は1刻みの降順を意味します。
つまり、aからb-(-1)まで降順で数えてリストにするという意味です。
例えば、range(9, 1, -1) = {9, 8, 7, 6, 5, 4, 3, 2}
となります。
今回だと、MAX_FONT_SIZEから9+1 = 10までの数値が1刻みで降順になってリストになります。そのリスト内の数値をひとつずつfont_sizeに代入して、次の処理をループで行っていきます。
テキストのフォント・サイズを決定
32行目
font = ImageFont.truetype(FONT_PATH, font_size)
ここでは、ライブラリのPILのモジュールであるImageFont.truetypeを使ってフォントの種類とサイズを決めています。
ImageFont.truetype(フォントのパス, フォントのサイズ)
でフォントを指定できます。
好きなフォントを使いたい時はfontsフォルダの中に使いたいフォントの.ttfファイルを入れておきます。
Imageフォントのテキストの幅と高さを決定
34行目
lines_size = [list(font.getsize(t)) for t in text]
ここでは、先ほど指定したImageフォントのテキストの1文字1文字の幅と高さを計算しています。
textは24行目で出てきた画像に入れる文字でしたね。
ImageFont.getsize(text)
はImageフォントのweight(幅)とheight(高さ)を(weight, heght)という風にタプルで返してくれます。
また、list()は、タプルをリストにしてくれる関数です。
for t in text
で、テキストの文字を一文字一文字変数tに代入して、テキストを画像フォントにした時の(weight, heght)をタプルとして取得。
それをリスト化して、最終的にはlines_size という変数に代入しています。
ループ処理を終了する指示
37行目
area_x = np.max(lines_size, 0)[0]
np.maxによって、lines_sizeの最大値を取り出して、area_xと定義します。
38行目
area_y = np.sum(lines_size, 0)[1]
np.sumによって、lines_sizeの合計値を取り出して、area_yと定義します。
40から41行目
if(area_x <=?TEXT_SIXE[0] and area_y?<=?TEXT_SIXE[1]):
break
・area_xはTEXT_SIXE[0]と等しいか、それより小さい。
・area_yはTEXT_SIXE[1]と等しいか、それより小さい。
この2つの条件が両方とも成立する時、for文によるループ処理を止めます。
アイキャッチ画像を指定したサイズにする
44行目
img = Image.open(os.path.join(INPUT_DATA_DIR, img_path))
ここでは、テキストを挿入したい画像ファイルを読み込みます。
そして、読み込んだ画像ファイルをimgと定義します。
os.path.join()はパスの要素を結合するモジュールでしたね。
詳しくはこちらを参照して下さい。
45行目
original_img_size = img.size
読み込んだ画像のサイズを取得します。
img.sizeでは、画像の(幅, 高さ)という、2つの要素をタプル形式で取得できます。
この2つの要素(タプル)を、original_img_sizeという変数に代入します。
画像の縦横比をチェックするif文
48行目
if (original_img_size[0] / original_img_size[1]) \
>=?(IMG_SIZE[0] / IMG_SIZE[1]):
ここからは画像のサイズをもとにして、規定のサイズ内に縮小して納める処理を行っていきます。
11行目でIMG_SIZE = (780, 428)として、横幅780、高さ428(単位はピクセル)が規定値として定めましたよね。
つまり、上記は目標の画像サイズ(IMG_SIZE)より、横長か縦長か判断するif文です。
45行目で、original_img_sizeは(幅, 高さ)の形のタプルでしたよね。
a = (第1要素, 第2要素)というタプルがあった場合、a[0]で第1要素を、a[1]で第2要素を示します。
よって、()内の変数は以下のようになります。
・original_img_size[1]=読み込んだ画像の高さ
・IMG_SIZE[1]=出力したいアイキャッチ画像の高さ
上記を踏まえた上でif文を実行すると、結果は2パターンに分かれます。
横長or縦長によって別ルートへ分岐
①「読み込んだ画像の幅/高さ」が、「出力したい画像の幅/高さ」より大きい場合
わかりやすく書くと、読み込んだ画像の縦横比が、出力したい画像より横長な場合です。
if文が成立するので、そのまま次の処理に進みます。
②「読み込んだ画像の幅/高さ」が、「出力したい画像の幅/高さ」より小さい場合
わかりやすく書くと、読み込んだ画像の縦横比が、出力したい画像より縦長な場合です。
if文が成立しないので、elseの処理まで進みます。
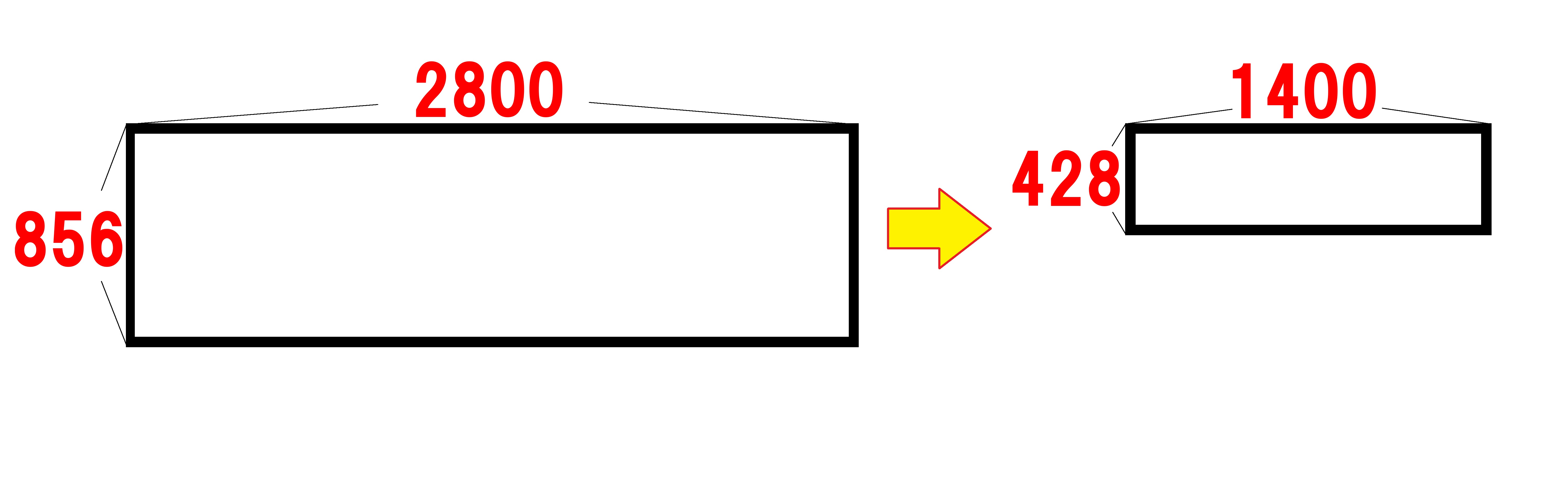
横長の場合①縦幅を縮める
出力したいサイズの縦横比に対して、読み込んだ画像の縦横比が、横に長い場合です。
まずは縦横比を維持したまま、縦幅を目標まで縮めます。
続いて、不要な横幅を切り抜くことで、高さも目標と同じに揃えます。
それが51行目からの処理です。
img.thumbnail((original_img_size[0], IMG_SIZE[1]))
img.thumbnail()モジュールはimg.thumnail(横幅, 高さ)のように記述して、
画像を()のサイズに収まるように縦横比を維持したまま縮小します。
この時点では横長のままでよいので、以下のサイズに収まる形に縮小します。
・横幅=original_img_size[0]=読み込んだ画像の幅
・高さ=IMG_SIZE[1]=出力したいアイキャッチ画像の高さ
52行目
thumbnail_size = img.size
この縮小した画像の幅と高さを取得し、thumbnail_sizeに代入します。
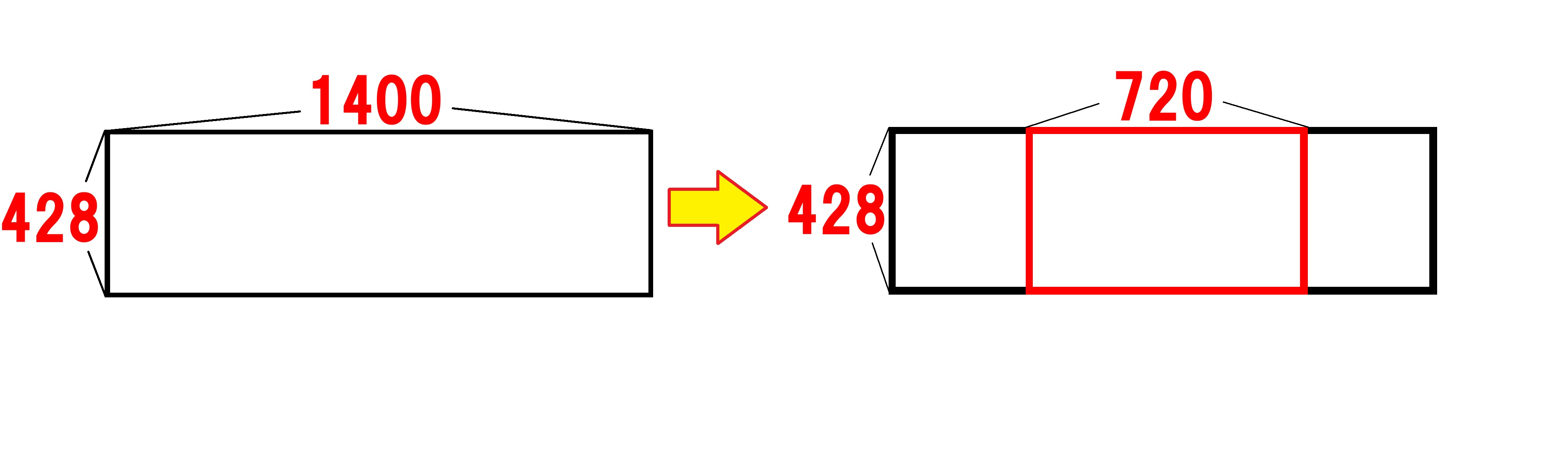
横長の場合②横幅を切り取る
①の縮小で、出力したいアイキャッチ画像と同じ高さにできました。
次は横幅を切り取ることで、出力したいアイキャッチ画像の幅を目指します。
54行目から57行目
crop_left = int((thumbnail_size[0] - IMG_SIZE[0]) / 2)
切り取り範囲の左上のx座標は、(縮小した画像の幅-出力したい画像)/2です。
int()関数によって、()に指定した数値を超えない、最大の整数を取得します。
crop_upper = 0
切り取り範囲の左上のy座標は、始点になる0です。
crop_right = crop_left + IMG_SIZE[0]
切り取り範囲の左上のx座標は、左側の余白+出力したい画像の横幅です。
crop_lower = IMG_SIZE[1]
切り取り範囲の右下のy座標は、出力したいアイキャッチ画像の高さです。
切り取りたいサイズを取得した後はelse文をスキップして、画像の切り抜きを実行します。
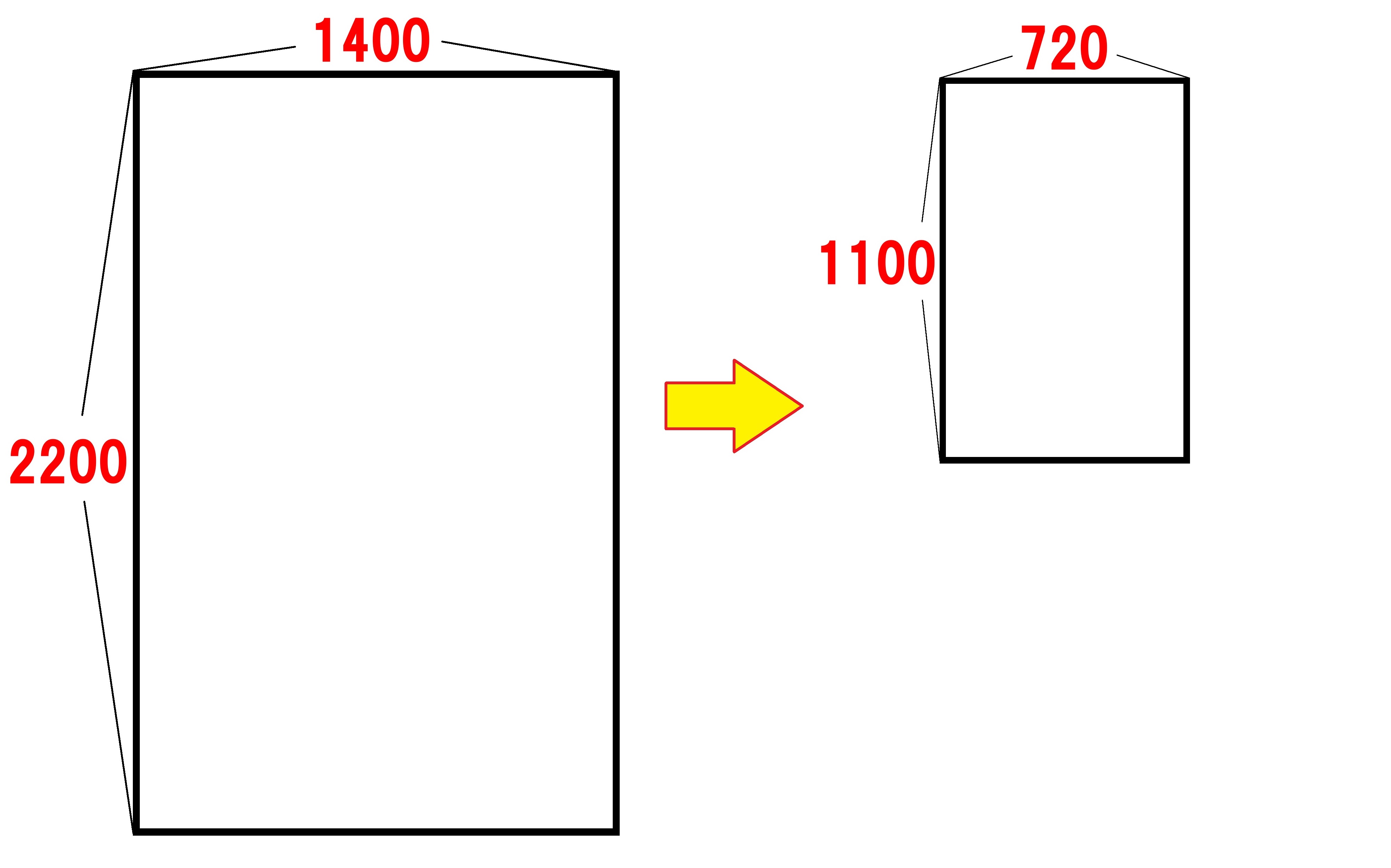
縦長の場合①横幅を縮める
出力したいサイズの縦横比に対して、読み込んだ画像の縦横比が、縦に長い状況です。
はじめに縦横比を維持したまま、横幅だけを出力したい画像に揃えます。
続いて、縦幅を切り抜くことで、不要な高さをカットします。
60行目
else以下の処理です。
img.thumbnail((IMG_SIZE[0], original_img_size[1]))
先ほど出てきたthumbnail()を使って、()のサイズに収まるように画像を縮小します。
この時点では縦長のままでよいので、以下のサイズに収まる形に縮小します。
・横幅=IMG_SIZE[0]=出力したいアイキャッチ画像の幅
・高さ=original_img_size[1]=読み込んだ画像の高さ
thumbnail_size = img.size
この縮小した画像の幅と高さを取得し、thumbnail_sizeに代入します。
縦長の場合②縦幅を切り取る
①の縮小で、出力したいアイキャッチ画像と横幅を同じにできました。
続いては縦幅を切り取ることで、出力したいアイキャッチ画像の高さを目指します。
crop_left = 0
切り取り範囲の左上のx座標は、始点である0にします。
crop_upper = int((thumbnail_size[1] - IMG_SIZE[1]) / 2)
切り取り範囲の左上のy座標は、(出力したい画像の縦幅 – 縮小した画像の縦幅)/2です。
int関数は引数に指定した数値や文字列を、整数にして取得します。
crop_right = IMG_SIZE[0]
切り取り範囲の右下のx座標は、出力したいアイキャッチ画像の幅そのままです。
crop_lower = crop_upper + IMG_SIZE[1]
切り取り範囲の右下のy座標は、上側の余白+出力したい画像の縦幅です。
これらの数値を使って画像の切り抜きを実行します。
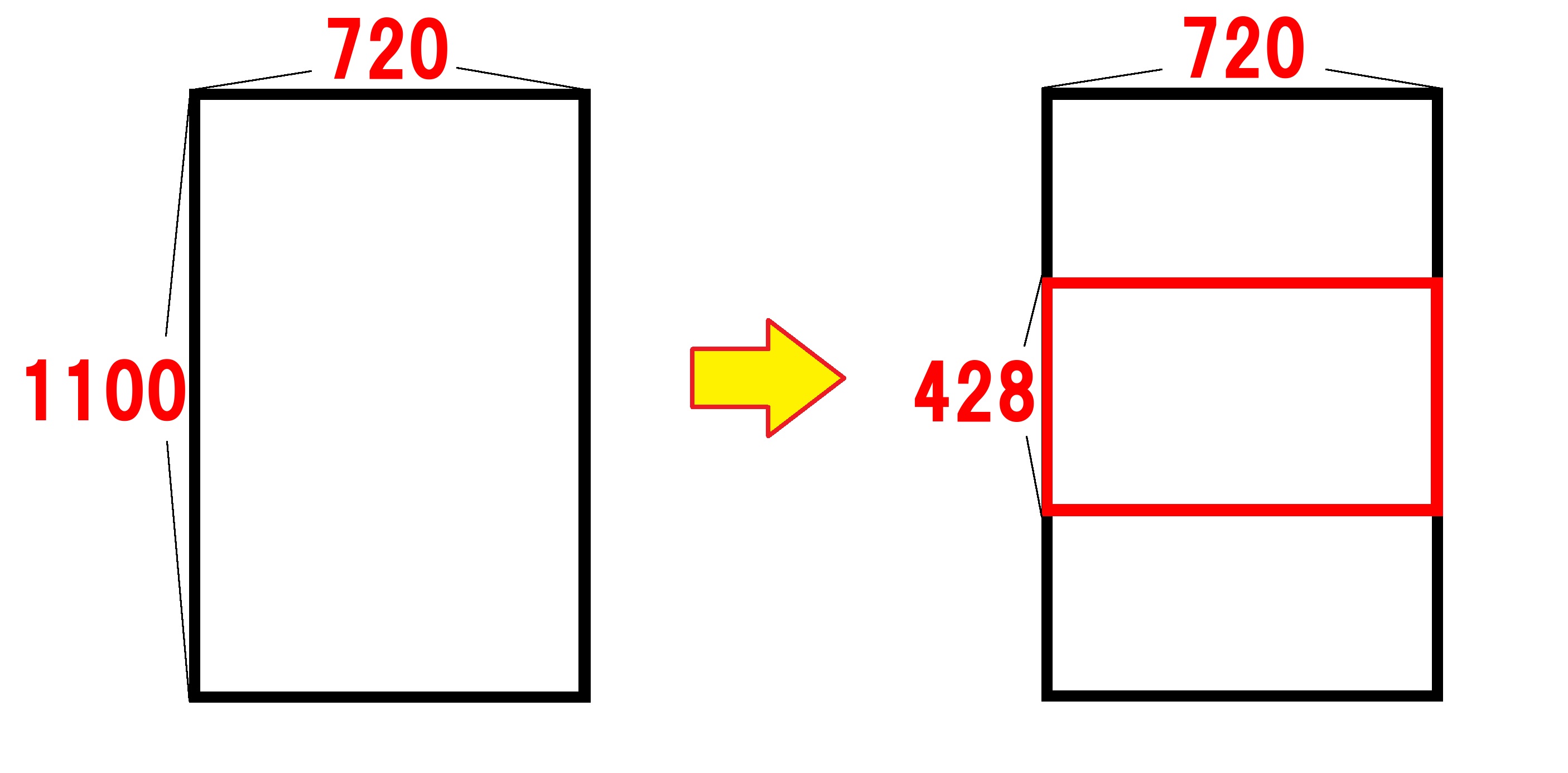
実際に画像を切り取る処理
69行目
img = img.crop((crop_left, crop_upper, crop_right, crop_lower))
ここでようやく画像を切り取る処理をしています。
img.crop()モジュールによって、()内に書かれた範囲で切り取った画像を作成します。
切り取り範囲については、以下のような形式で指定しています。
img.crop(左上のx座標,左上のy座標,右下のx座標,右下のy座標)
・crop_left=切り取り範囲の左上のx座標
・crop_upper=切り取り範囲の左上のy座標
・crop_right=切り取り範囲の右下のx座標
・crop_lower=切り取り範囲の右下のy座標
横長の場合と縦長の場合、それぞれのパターンで算出した数値を代入します。
こうして切り抜いた画像を、imgという変数に代入しています。
アイキャッチ画像に文字を挿入する
72行目から73行目
画像を目標のサイズにトリミングできたので、テキストを挿入していきます。
まずはテキストの設定に必要な、2つの引数を用意します。
rectangle_y = area_y + TEXT_MARGIN
area_yと、テキストの余白の合計を、rectangle_yという変数に代入します。
rectangle_top = int((IMG_SIZE[1]-rectangle_y)/2)
(出力ファイルの高さ-rectangle_y)/2の整数を、rectangle_topという変数に代入します。
アイキャッチに挿入する文字色の設定
76行目
for (label, fg_color, bg_color) in TEXT_COLORS:
TEXT_COLORSから、label, fg_color, bg_colorの3つの要素を変数として、以降の処理を実行します。
・label=名前
・fg_color=前景色
・bg_color=背景色
今回のTEXT_COLORSには、黒と白の2色分の数値が設定されているので、
2回の処理が行われ、2枚のアイキャッチ画像が作成されます。
テキストを挿入するレイヤー画像を作成
78行目から79行目
rectangle_img = Image.new('RGBA', img.size)
Image.new()は、Image.new(画像形式, 画像サイズ)で()内の条件で画像を新規に作成します。
78行目では、img.sizeで指定したサイズの画像をRGBA形式で新規作成します。そして作成した画像を、rectangle_imgという変数に代入しています。
画像の中に四角形を描く
画像の中に四角形を描く場合、
draw = ImageDraw.Draw(画像イメージ) draw.rectangle((左上の座標,右下の座標),塗つぶし色,線色)
のように記述します。意味としては、
ImageDrawモジュールのDrawメソッドを用いており、
draw = ImageDraw.Draw(画像イメージ)でまず画像イメージに書き込めるレイヤーを作成。
そして、draw.rectangle((左上の座標,右下の座標),塗つぶし色,線色)でそのレイヤーに対して四角形を書き込んでいくという2段階の処理をしています。
79行目
draw = ImageDraw.Draw(rectangle_img)
この行でrectangle_imgに書き込みできる透明なレイヤー画像をまず作っています。
挿入する文字の背景になる四角形の領域を描画
80行目
draw.rectangle((0, rectangle_top, IMG_SIZE[0],
rectangle_top+rectangle_y), bg_color)
.rectangle()は四角形を描写するメソッドです。
bg_colorの色で、以下のように座標を使って設定したサイズの四角形を先ほどのdrawというレイヤーに描画します。
四角形を書き込みする座標は
・塗りつぶす範囲の左上のx座標=0
・塗りつぶす範囲の左上のy座標=rectangle_top
・塗りつぶす範囲の右下のx座標=IMG_SIZE[0]
・塗りつぶす範囲の右下のy座標=rectangle_top+rectangle_y
となっています。
透過で描写できるRGBA形式に変換
84行目
org_img = img.convert('RGBA')
img.convert(RGBA)によって、画像imgをRGBA形式に変換します。
透明度ありのRGBAに変換することで、画像imgに透明な処理を行うことができます。
こうしてRGBA形式になった画像imgを、org_imgという変数に代入します。
アイキャッチ素材にレイヤー画像を重ねる
85行目
new_img = Image.alpha_composite(org_img, rectangle_img)
ここは画像を重ねる処理です。
Image.alpha_composite(img_a, img_b)によって、img_aの画像の上にimg_bの画像を重ねることができます。
つまり、85行目では画像org_imgに画像rectangle_imgを重ねています。
これはつまり、先ほどトリミングした画像の上にテキストを入れる予定のレイヤーを重ねるという意味です。
2つの画像を重ねた完成形の画像を、new_imgという変数に代入しています。
画像にテキストを描画する処理
87行目
draw = ImageDraw.Draw(new_img)
次にテキストを描画するためのレイヤーを作っています。
ImageDraw.Draw()を使って、new_imgのレイヤーを作り、以下の描写を加えていきます。
88行目
_y = int((IMG_SIZE[1]-area_y)/2)
(出力したい画像の高さ-area_y)/2の値を、int()で整数にして、_yという変数に代入しています。
89行目
for (t, line) in zip(text, lines_size):
ここで、zip()は複数のリストの要素をまとめて取得する関数です。
textとlines_sizeという文字列のリストから、1文字1文字取り出してそれぞれtとlineという変数に代入して以下の処理を行っていきます。
90行目
_x = int((IMG_SIZE[0]-line[0])/2)
(出力したい画像の横幅-lineの第1要素)/2の整数を、_xと定義します。
draw.text関数でテキストを描写
91行目
draw.text((_x, _y), t, font=font, fill=fg_color)
draw.text()関数を用いて、()に指定した条件で文字を描写します。
draw.text(position, message, fill, font)
・position:文字を描写したい場所(xy座標)
・message:描写したい文字の内容
・fill:描写したい文字の色(RBG形式)
・font:描写したい文字のフォント
という形で、()内で指定した文字内容、文字色、フォント、テキストの場所でテキストを描写してくれます。
今回の場合は、座標(_x,_y)に、色はfg_color、フォントはfontで、tという内容の文字を挿入します。
92行目
_y += line[1]
_yの値にline[1]の値を足して、その値を_yに代入します。
Pythonでは、
x += y
で x = x + yの意味になります。
RGB形式に再変換して、jpgファイルで保存する
94行目
new_img = new_img.convert("RGB")
new_imgという画像を、RGB形式に変換して、new_imgという変数に代入します。
jpegで画像を保存するには、RGBAからRGB形式に変換する必要があるからです。
95行目
res_file_name = file_name + "_" + label + ".jpg"
img_pathにある画像のファイル名+_+label.jpgという文字列を、res_file_nameという変数に代入します。
96行目から97行目
new_img.save(os.path.join(OUTPUT_DATA_DIR, res_file_name),
quality=IMG_Q)
new_img.save()によって、()に指定したパスで画像を保存します。
ここではos.path.join()を用いて、OUTPUT_DATA_DIRとres_file_nameのパス名を連結し、新しいパスとしています。
quality=IMG_Qでは、保存する画像のクオリティを設定しています。
save()関数は、()内の拡張子から自動で保存フォーマットを判定してくれます。
jpgの場合、qualityで保存する画像の品質を変更する事ができるので、IMG_Qの値に設定しました。
98行目から99行目
plt.figure()
plt.figure()では、新しいウィンドウを描画します。
plt.imshow(new_img)
plt.imshow()を使って、new_imgを貼り付けます。
ここまでの処理が、make_eye_catch()関数になります。
main関数
102行目
def main():
def文によって、以下に続く処理をmain関数として定義しています。
CSVファイルを読み込む
103行目
input_data_list = []
input_data_listという変数にリストを代入しています。
106行目
with open(SETTING_CSV, "r", encoding="shift-jis") as csv_file:
SETTING_CSVファイルを文字コードshift-jis形式でcsv_fileとして読み込みます。
"r"は読み込み専用で読み込むという意味です。
107行目
reader = csv.DictReader(csv_file)
csv_fileファイルから読み込まれた、個々の列の情報をオブジェクトとして生成します。
for row in reader:
input_data_list.append([row["path"], row["sentence"]])
for文によって、読み込んだ情報を1つずつinput_data_listのリストへ追加しています。
outputフォルダを作成する
112行目
if not os.path.exists(OUTPUT_DATA_DIR):
os.path.exists()関数を使ってファイルやフォルダが存在しているかどうかを確認することができます。
上では、OUTPUT_DATA_DIRつまり、画像を出力するoutputディレクトリが存在するか調べます。
もし存在しない場合、if文が成立するので、次の行の処理を行います。
113行目
os.makedirs(OUTPUT_DATA_DIR)
OUTPUT_DATA_DIRが存在しない場合、「output」という名前のフォルダを作成します。
os.makedirs()関数は、新規ディレクトリ(フォルダ)を作成する関数です。
アイキャッチ画像を作成する
116行目
for img_path, text in input_data_list:
img_path, textという変数に、input_data_listを入れて続く処理を繰り返していきます。
ここ以降では、CSVファイルに記載してある画像のファイル名とテキストによってアイキャッチ画像を繰り返し作っていく処理を実行していきます。
117行目
make_eye_catch(img_path, text)
make_eye_catch()関数を、img_path, textという変数で実行します。
ここで指定したテキスト入りのアイキャッチ画像が作成されます。
作業完了のメッセージを表示させる
118行目
info_msg = "[INFO] {0}の処理が完了しました"
print(info_msg.format(os.path.join(INPUT_DATA_DIR, img_path)))
print("[INFO] Finish!!")
prog.pyの作業が完了すると、printによって以下のメッセージが表示されるよう設定しています。
[INFO]入力ファイルのパス名\入力した画像ファイル名.jpgの処理が完了しました
[INFO] Finish!!
他のプログラムからは実行できないよう設定
if __name__ == "__main__":
main()
if文が成立する場合のみ、先ほど定義したmain関数を実行するようにします。
prog.pyを実行した場合のみ、__name__に’__main__’という値が代入され、if文が成立します。
この設定を加えることで、他のプログラムからimportされた際に、main関数が実行されません。
プログラムを実行していただいたり、改良して@uury112をつけてメンション付きのツイートをしていただければ(https://twitter.com/uuyr112)でリツイートさせていただきます。


コメント